|
|
ITWeb/스크랩 2008. 6. 19. 15:47
-
테스트는 프로그램이나 시스템이 자신이 해야 되는 일을 수행하는 믿음을 주는 과정이다. [Hetzel 73]
-
컴퓨터 소프트웨어를 실행하여 그 결과가 올바른지 판단하는 과정이다. [Glass 79]
-
에러를 발견한 목적으로 프로그램을 실행하는 과정이다. [Myers 79]
-
프로그램 테스트는 오류가 존재함을 보일 수는 있지만, 오류가 없음을 보일 수는 없다 [Dijkstra 72]
-
테스트는 소프트웨어 품질을 측정하고 개선하기 위한 테스트웨어를 공학화하여 사용하고 유지하기 위한 또 다른 아이프사이클 프로세스이다. [Crag and Jaskiel 02]
-
요구사항의 잘못된 정의 -
-
고객과 개발자간의 잘못된 의사 소통이나 부재
-
고의적인 요구사항 미 준수
-
설계 오류
-
코딩 오류
-
문서나 코딩 표준에 따르지 않는 경우
-
미흡한 테스트 프로세스
-
단위테스트 : 구현 단계에서 각 모듈이 구현된 후에 단위 테스트를 수행, 모듈이 단독적으로 실핼할 수 있는 환경 필요
-
통합테스트 : 단위 테스트가 완료된 모듈 간의 인터페이스 상호작용이 올바르게 되는지를 테스트함으로써 (1) 개별적인 모듈에 대한 테스트가 불충분하게 수행됨을 보완 (2) 제한된 상황만을 고려한 테스트 스텁 때문에 실제 모듈과 통합하는 과정에서 오류가 발생을 확인 (3) 전역 변수 등으로 인해 모듈간의 예기치 못한 상호 작용 때문에 발생하는 부작용(side effect) 인한 오류 발생 부분을 확인 가능하다.
-
빅뱅테스트
-
점진적 테스트
-
하향식 통합 : 가장 상위 모듈을 테스트하기 위해 하위 모듈들을 테스트 스텁들로 대치한 후에 테스트를 수행하는 방식임. 설계상의 오류를 빨리 발견할 수 있다는 장점이 있는 반면에, 많은 수의 테스트 스텁이 필요하기 때분에 비용이 많이 소요될 수 있다. 블랙박스 테스트만 사용하는 경우 하위 모듈이 충분하게 테스트되지 않을 가능성 있음.
-
상향식 통합 : 하위 모듈을 먼저 테스트하고 상위에 있는 모듈들을 통합하는 방식임. 하위에 있는 모듈들을 충분하게 테스트할 수 있고, 테스트 스텁 비용이 들지 않는 장점이 있는 반면 설계 오류를 조기에 발견하는 못하는 단점이 있다.
-
샌드위치 통합 : 하향식+상향식의 통합하는 방법
-
시스템 테스트 : 전체 시스템에 대한 초기의 목적을 만족시키는가를 테스트로 통합 테스트가 완료된 후에 완전한 시스템에 대해 시스템 명세에 따라 개발되었는지를 검증하기 위해 수행하는 테스트임. 단위 테스트나 통합 테스트는 기능이 올바르게 수행되는지를 검증하는 것에 중점을 두지만, 시스템 테스트는 시스템의 기능 측면에서뿐만 아니라 신뢰성, 견고성, 성능, 안정성과 같은 비기능적 요구사항을 시스템이 만족하는 지도 검증함.
-
테스트드라이버 역할
-
테스트 케이스가 저장되어 있는 파일이나 DB로부터 하나의 테스트 케이스를 읽는다.
-
읽은 테스트 케이스를 입력 인자로 사용하여 테스트 대상이 되는 모듈을 호출한다.
-
모듈의 실행 결과를 저장하고 다음 테스트 케이스를 읽는다. 경우에 따라서는 테스트 드라이버가 테스트 오라클 역할을 수행할 수 있다. (즉 실행결과가 원하는 결과인지를 판별하여 프로그램에 오류가 검출되었는지를 판별하는 기능을 수행)
-
2-3과정을 더 이상 실행할 테스트 케이스가 없을때까지 반복하여 수행
-
-
동등분할 클래스
-
경계값 분석
-
결정 테이블 기반 테스트
-
도메인 테스트
-
Pairwise 테스트
-
상태 전이 테스트
-
Cause-effect graph
-
화이트박스 테스트 : 프로그램 코드 정보 (제어 및 자료흐름)을 바탕으로 테스트 케이스 작성
-
제어흐름 기반 테스트
-
자료흐름 기반 테스트
-
결함 기반 테스트
-
침입(penetration) 테스트 - 시스템의 보안을 테스트
-
견고성(robustness) 테스트 - 시스템이 비정상적인 운영환경하에서 얼마나 동작이 원활하게 이루어 지는지를 시험
-
네거티브 테스트 : 시스템이 기대하지 않는 입력들을 테스트 데이터로 사용
-
성능 테스트
-
스트레스 테스트 및 볼륨 테스트
-
신뢰성(reliability) 테스트 - 시스템이 어느 기간 동안에 요구되는 서비스를 제공하는 능력을 측정, 통계적 테스트(statistical testing)방법을 사용함.
-
가용성(availability) : 시스템이 주어진 기간 동안 서비스를 실제로 제공할 수 있는지 나타내는 속성 (ex : 가용성이 0.995 : 시스템은 1,000시간 단위 동안 995시간 단위 동안 서비스를 제공)
-
MTTF(mean time to failfure) : 시스템이 운영된 후 오류가 발생할 때까지의 평균 동작 시간 (ex : MTTF가 100 : 100시간 단위마다 1개의 오류가 발생할 수 있다는 것을 의미 )
-
컴파일러 테스트
-
임베디드 시스템 소프트웨어
-
운영 체제
-
웹시스템
-
컴포넌트 테스트
-
테스트는 반드시 프로그램을 개발한 프로그래머나 팀과는 무관한 그룹에 의해서 수행되어야 한다.
-
테스트 작업을 가장 능력이 뛰어난 사람에 할당하라.
-
오류가 발견되지 않을 것이란 가정하에서 테스트 계획을 수립해서는 안된다.
-
타당한 경우뿐만 아니라 타당하지 않고 예상하지 못한 경우들에 대해서도 테스트를 수행하라.
-
프로그램의 어떵 부분에 오류가 남아있을 확률은 이미 발견된 오류의 수에 직접적으로 비례한다. (Pareto원칙)
-
테스트 케이스를 체계적으로 관리하라
-
각각의 테스트 결과를 철저하게 검증하라
-
Tester : 누가 테스트를 수행하는가?
-
사용자 테스트, 알파, 베타, 전문가, 짝 테스트
-
범위 : 어떤 측면을 테스트 하는가?
-
함수, 기능 또는 통합 함수, 메뉴, 도메인, 동등 클래스, 경계값, 입력 필드, 논리, 상태, 경로, 요구사항, …
-
잠재적 문제(risk based) : 찾고 있는 문제의 형식은?
-
행위 : 어떤 테스트를 수행하는가?
-
회귀, 스크립트 기반, 시나리오, 설치, 부하, 성능…
-
평가 : 테스트를 통과했는지 어떻게 알 수 있을까?
-
소스코드 관리 시스템을 사용하고 있습니까?
-
한번에 빌드를 만들어 낼 수 있습니까?
-
일일 빌드를 하고 있습니까?
-
버그 추적 시스템을 운영하고 있습니까?
-
코드를 새로 작성하기 전에 버그를 수정합니까?
-
일정을 업데이트하고 있습니까?
-
명세서를 작성하고 있습니까?
-
조용한 작업 환경에서 일하고 있습니까?
-
경제적인 범위 내에서 최고 성능의 도구를 사용하고 있습니까?
-
테스터를 별도로 두고 있습니까?
-
프로그래머 채용 인터뷰때 코딩 테스트를 합니까?
-
무작위 사용편의성 테스트를 수행하고 있습니까?
-
테스트 단계 활동 –> 모든 단계 활동
-
정상 수행 확인 –> 오류(Error) 발견
-
단위 테스트 중심 –> 시스템 테스트 중심
-
Know which test techniques work best
-
Automate retesting and test management
-
Minimize test design labor
-
Know when to stop testing
-
Configuration/설치 테스팅
-
HW 및 SW가 정확히 설치되었는가?
-
모든 파일과 연결(connection)이 생성되었는가?
-
모든 적절한 데이터 파일이 load되었는가?
-
System defaults가 적절히 구성되었는가?
-
다른 시스템과의 인터페이스 및 주변 기기가 잘 작동하는가?
-
호환성 및 상호운영성 테스팅
-
호환성: 실제 환경에서 운영할 때 기존의 시스템에 대해 오동작이 없는가?
-
상호운영성 : 실제 환경에서 대상 시스템을 운영할 때 다른시스템과 성공적으로 연동 하는가?
-
문서 및 도움말 테스팅
-
문서 검토, 상호 참조 등을 활용하여 작성해야 함, 신규 또는 익숙하지 않은 사용자의 경우 필수적임.
-
장애회복(Fault recovery) 테스팅
-
에러 또는 예외 상황 발생 후 정상 상태로 회복되어 성공적으로 운영될 수 있는가?
-
적절한 백업데이터가 유지되는가?
-
백업데이터가 안정한 장소에 저장되는가?
-
회복 절차가 문서화되어 있는가?
-
회복 전담요원이 할당되고 훈련되었는가?
-
회복 도구가 개발되고 가용한가?
-
성능 테스팅: 자동화 도구를 활용하는 경우가 많음.
-
어떤 측면을 주로 테스트할 것인가?
-
성능 요구사항은 무엇인가?
-
시스템 사용시 어떻게 변화되는가?
-
어떻게 시험하는가?
-
자동화된 테스팅
-
Test automation tools 활용 재사용 가능한 테스트 생성 및 예상결과외 실제 결과를 기록으로 남김)
-
적용분야 : 기능 테스팅, 성능/볼률/스트레스 테스팅, 특히 regression testing시 유용함
-
Intrusive 테스팅
-
테스트 결과를 테스터가 볼 수 없을 때 프로그램 일부를 수정하여 테스트 함
-
수정된 시스템은 원상 복귀하여야하며, 엄격한 change control 및 형상관리가 요구됨
-
Thread 테스팅
-
Business 기능을 처음부터 끝까지 테스트 함 (사용자 혹은 운영자가 시스템을 사용하는 것과 같은 방식)
-
ETC
-
Security 테스팅 - 요구되는 수준의 보안을 구현하였는지 테스트함 (비밀보장,가용성,데이터및 SW무결성을 점검)
-
Stress 테스팅 - Peak Load일 때 정확하게 작동하는지 점검
-
Usability 테스팅 - User-based surveys등 수행
-
Volume 테스팅 - 데이터의 양이 많을 때 정확하게 작동하는지 점검
-
Compliance 테스팅 - 표준 및 절차에 따라 개발되었는지 점검
ITWeb/스크랩 2008. 4. 17. 16:42
ref. http://channy.tistory.com/253최근들어 해외 '유명 성공 웹 서비스'의 국내 러시가 한창이다. 국내에도 많은 외국계 기업들이 있고 이들 중 IT 분야에 진출한 업체가 꽤 많다. 많은 외국계 IT기업들이 한국에 들어왔다가 철수하기를 반복하고 있다. 이런 현상은 IT 업계 뿐만 아니어서 흔히 말해 한국은 글로벌 기업의 무덤이라고 까지 한다. 이전에 다니던 회사에서 온라인 음악 비지니스를 하면서 느낀 것이 있다. 업의 성격상 음반사들과 많은 교류를 했었고, 같은 층에 EMI라는 외국계 직배 회사가 있었다. 물론 소니뮤직, 워너뮤직, BMG 등 다르 직배사들과도 제휴도 하고 안면을 트고 지냈다. 그런데 아주 재미있는 것이 몇 년 동안 각 직배사의 한국 지사장 교체 상황을 보면 거의 같은 업계 내에서 움직이는 현상을 볼 수 있었다. 소니에 있던 사장이 EMI로 가고 BMG에 있던 사장이 워너로 가는 것이다. 본사의 입장에서 보면 글로벌 본지사의 관계에 대한 경험이 있고 그쪽 시장을 잘 이해하는 사람을 쓰는 것은 당연한 귀결일 것이다. 이들은 영어도 잘하고 글로벌과 로컬 감각을 동시에 가지고 있으면서 본사가 원하는 것을 잘 맞추어 주는 인재들이다. 이런 현상은 외국계 음반 직배사에 한정 되지 않고 IT 업계에도 똑같이 통용된다. 즉, 인텔에 있던 분이 MS로 가고, IBM에 있던 사람이 썬으로 움직인다. 특히 임원급 이상에서는 그 정도가 더 심하다. 외국계 기업이 '지역화'에 실패하는 이유는 대부분 이러한 순환되는 관리형(?) 임원들에 의한 것인 경우가 많다. 실제로 이들 기업에 취업하는 많은 사람들이 국내 현지 인력들이고 이들은 국내 다른 경쟁사와 똑같이 서비스를 만들 수 있는 능력들을 가진 사람들이다. 하지만, 이들의 아이디어가 구현되기 위해서는 정말 많은 난관이 있다. 의사 결정 과정에서 시간이 많이 걸리고 투자 판단에 대한 리스크를 최소화 하기 위한 안전 장치가 만들어진다. 소위 외국에서 MBA를 하시고 국내에 어느 정도 인맥을 가지신 전문 경영인이라 불리는 분들이 글로벌 기업의 이러한 시스템에 따라 국내 사업을 총괄하는 경우가 많아 현지 직원들의 아이디어를 미리 차단하기도 해서 쉽게 구현되기 어렵게 되는 것이다. 게다가 사업이 지지부진해 최악의 경우 철수를 하더라도 쉽게 같은 분야의 다른 외국계 기업으로 옮겨 가기가 쉽다. 이들 '전문 경영인'들 뿐 아니라 한국에 진출하는 리스크 없이 성공하려는 글로벌 기업의 안일한 투자 및 의사 결정에도 물론 문제는 있다. 야후! 저팬이나 알리바바가 성공한 이면에는 지역 대형 사업자와의 지분 제휴를 통한 과감한 투자를 했던 점이 컸고 이러한 투자에 의해 지역의 우수한 인재들의 아이디어 실현이 힘입은바 크다. 국내 진출이랍시고 밑바닥 부터 흩을려는 각오가 아니라 관망 자세로 적극적 투자를 게을리 하는 본사에게도 문제가 있는 것이다. 하지만, 외국계 기업에 근무하는 대부분의 사람들은 항상 외국계 기업으로만 전직을 하는 커리어 패스를 따라가는 현상이 나타나고 있고, 이러한 인력의 정체와 순환은 결국 로컬 사업에 영향을 주게 된다. 국내에서도 과거 야후!코리아나 라이코스 코리아의 경우를 비추어 보더라도 초기의 과감한 투자와 아이디어가 갈수록 빛이 바랬었고, 옥션의 경우도 이베이 인수 이후 지마켓에 따라잡히는 상황이 연출 되기도 했다. 만약 구글코리아가 네이버의 현직 서비스 담당 임원을 영입했다면 어떻게 되었을까? 결국 모든 것은 사람의 문제이다. 결국 모든 것은 사람의 문제이다.. 이 부분.. 마음에 많이 와닿내요.. 그리고 글로벌 회사의 고질적인 문제점도 역시라는 ...
ITWeb/스크랩 2008. 3. 31. 16:45
이런게 있내요. 지난번 네이버와 다음을 비교 했던 내용과는 사뭇 다르지만.. 개발자 스스로 나는 어디쯤 와 있는지 확인해 볼 필요도 있겠내요.. 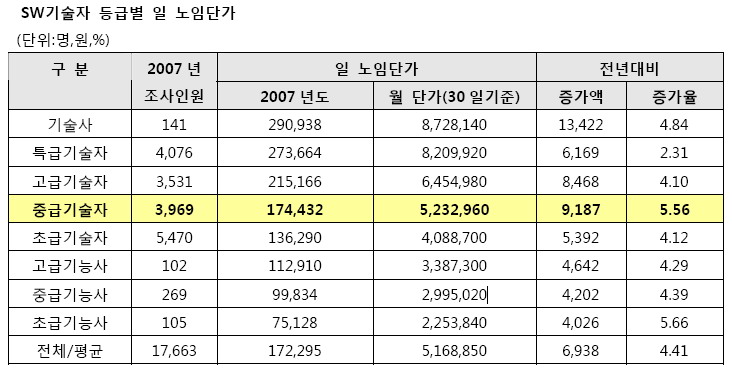 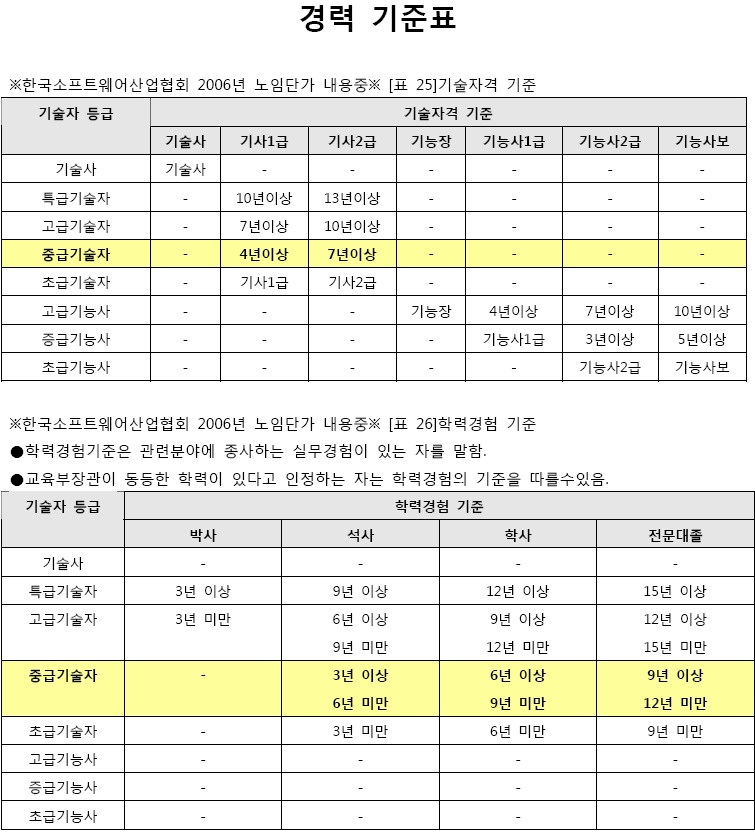 기술자격 기준에 의한 고급기술자 (기사 1급 보유) 학력 기준에 의한 중급기술자 (아직 만 9년이 안되어서.. ) 근데 노임으로 보면.. 저는 정말 좌절 이군요.. 이거 회사에 따져야 하나.. 된장.. 일은 빡시게 하는데.. pay 는 왜 이래.. - 실력이 없거나 인정을 못받고 있거나 ㅡㅜ^
ITWeb/스크랩 2008. 3. 28. 11:15
ref. http://en.wikipedia.org/wiki/Cloud_computing
Cloud computing
From Wikipedia, the free encyclopedia
Cloud computing is a new (circa late 2007) label for the subset of grid computing that includes utility computing and other approaches to the use of shared computing resources. Cloud computing is an alternative to having local servers or personal devices handling users' applications.
In general, the label suggests that function comes from "the cloud" -- often understood to mean a public network, usually assumed to be the Internet -- rather than from a specific identifiable device. The label of "cloud computing" is not, however, identical with the business model of software as a service or the usage model of utility computing. Grid computing is a technology approach to manage a cloud. In effect, all clouds are managed by a grid but not all grids manage cloud. Specifically a computer grid and a cloud are synonymous while a data grid and a cloud can be different.
Within the general label, though, it is an easy error to assume that all clouds are created equal. This can lead to confusion and disappointment.
For example, virtualization of servers on a shared super-server can speed the deployment of new capability, since no new hardware needs to be installed, but the software stack that runs on the virtual server must still be configured and updated -- unlike the case with a multi-tenant software-as-a-service capability.
A computer cluster can offer cost-effective service in specific applications, but may be limited to a single type of computing node that allows all nodes to run a common operating system. Alternatively, the canonical definition of grid is one that allows any type of processing engine to enter or leave the system, dynamically, by analogy to an electrical power grid on which any given generating plant might be active or inactive at any given time.
However, an electrical generator only needs to produce volts and amperes in synchrony with other units on the grid, while computing cycles are not nearly such an undifferentiated commodity. For example, a computing grid could include both general-purpose processors and specialized units such as a vector processor facility.
Also important to the notion of cloud computing is the automation of many management tasks. If the system requires human management to allocate processes to resources, it's not a cloud: it's just a data center.
The applications of cloud/utility computing models are expanding rapidly as connectivity costs fall, and as evolution of processor architectures favors the development of multi-core systems with intrinsically parallel computing hardware that greatly exceeds the parallelization potential of most applications. The economic incentives to share hardware among multiple users are increasing; the drawbacks in performance and interactive response that used to discourage remote and distributed computing solutions are being greatly reduced.
As a result, the services that can be delivered from the cloud are not limited to web applications, but may also include storage, raw computing, or access to any number of specialized services.
Common visualizations of a cloud computing approach include, but should not be considered to be limited by, the following:
[edit] Potential advantages
Potential advantages of any cloud or grid computing approach include:
- location of infrastructure in areas with lower costs of space and electricity
- sharing of peak-load capacity among a large pool of users, improving overall utilization
- separation of infrastructure maintenance duties from domain-specific application development
[edit] Ensembles
While most traditional IT clouds are made up of heterogeneous systems, an ensemble is a pool of homogenous systems within the cloud which are compatible with one another. These ensembles are integrated by virtualization and management software which allow for mobility of the software stack between physical servers. It can scale from a few servers to many thousands, while having the management complexity near that of a single system. For instance an ensemble could be a set of systems which are capable of running a certain web appliance stack. The operating system, middleware, and web-app run exactly the same between servers in the ensemble.
[edit] Architecture
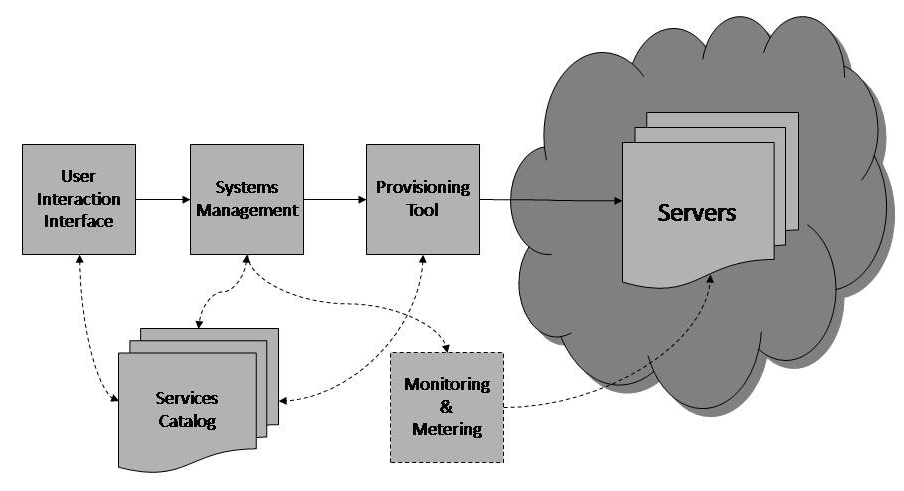
Diagram of cloud computing architecture.
The architecture behind cloud computing is a massive network of "cloud servers" interconnected as if in a grid running in parallel, sometimes using the technique of virtualization to maximize computing power per server.
A front-end interface allows a user to select a service from a catalog. This request gets passed to the system management which finds the correct resources, and then calls the provisioning services which carves out resources in the cloud. The provisioning service may deploy the requested stack or web application as well.
- User interaction interface: This is how users of the cloud interface with the cloud to request services.
- Services catalog: This is the list of services that a user can request.
- System management: This is the piece which manages the computer resources available.
- Provisioning tool: This tool carves out the systems from the cloud to deliver on the requested service. It may also deploy the required images.
- Monitoring and metering: This optional piece tracks the usage of the cloud so the resources used can be attributed to a certain user.
- Servers: The servers are managed by the system management tool. They can be either virtual or real.
[edit] Cloud storage
Cloud storage is a model of networked data storage where data is stored on multiple virtual servers, generally hosted by third parties, rather than being hosted on dedicated servers. Hosting companies operate large data centers; and people who require their data to be hosted buy or lease storage capacity from them and use it for their storage needs. The data center operators, in the background, virtualize the resources according to the requirements of the customer and expose them as virtual servers, which the customers can themselves manage. Physically, the resource may span across multiple servers.
[edit] Cloud services
Cloud services refers to web services offered via cloud computing. Amazon is probably the first company to start selling Cloud based services in the form of its Amazon Elastic Compute Cloud, popularly known as Amazon EC2, a part of Amazon's web services platform. Currently in its beta version, it provides computing capacity in the cloud to run applications
ITWeb/스크랩 2008. 3. 21. 18:04
ref. http://www.w3.org/TR/2008/WD-XMLHttpRequest2-20080225/
w3c 에서 2월 25일에 올라온 겁니다.
이건 기본적으로 필요로 하는 환경이 DOM2Event, DOM3Core, HTML5 에서 정상 작동 합니다.
못보던 method 들도 있고 cross-site access request 에 대해서도 지원이 되는듯 하내요..
참고. http://www.w3.org/TR/access-control/
그리고 예전에는 status 를 계속 확인해야 했었지만.. 지금은.. event 를 지원해 주고 있어서 코딩 하기 좀더 쉬워진 느낌 이내요.
원문을 저도 다 읽어 보지는 못하고 그냥 훑어 본거라.. 관심 있으신 분들은.. 한번 읽어 보세요.. ^^*
T.G.I.F
ITWeb/스크랩 2008. 3. 13. 13:20
Channy's Blog 에서 퍼온 이미지 입니다. ref. http://channy.tistory.com/238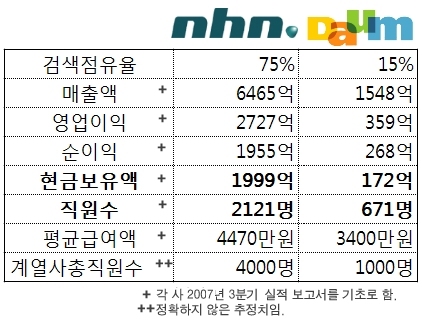 당신은 포털과 같은 인터넷 업체에서 일을 하십니까? 그럼 당신의 연봉은.. 얼마나 되십니까? 흠.. 저는 네이버 평균 보다 적고 다음 평균 보다는 많내요.. 연봉 = 몸값 = 능력 이런 동등의 관계가 성립이 되는 걸까요? 몸집을 키우지 말고 내실을 다지는게 회사나 정말 성실하고 실력 있는 직원들에게 좋은게 아닌가 싶기도 하내요.. 몸집 키우기에 동참하는 거품맨들과 정말 성실히 일하는 직원들 등쳐먹는 인간들은.. 언넝 반성해 주세요..
ITWeb/스크랩 2008. 3. 11. 17:28
ref. http://download.oracle.com/docs/cd/A58617_01/server.804/a58246/distrib.htm
remote and distributed query 에 대한 성능 정보를 찾다가 oracle tuning 에서 이런게 있길래 퍼왔습니다.
^^*
Summary: Optimizing Performance of Distributed Queries
You can improve performance of distributed queries in several ways:
- Choose the best SQL statement.
In many cases there are several SQL statements which can achieve the same result. If all tables are on the same database, the difference in performance between these SQL statements might be minimal; but if the tables are located on different databases, the difference in performance might be bigger.
- Use cost-based optimization.
Cost-based optimization can use indexes on remote tables, considers more execution plans than rule-based optimization, and generally gives better results. With cost-based optimization performance of distributed queries is generally satisfactory. Only in rare occasions is it necessary to change SQL statements, create views, or use procedural code.
- Use views.
In some situations, views can be used to improve performance of distributed queries; for example:
- to join several remote tables on the remote database
- to send a different table through the network
- Use procedural code.
In some rare occasions it can be more efficient to replace a distributed query by procedural code, such as a PL/SQL procedure or a precompiler program. Note that this option is mentioned here only for completeness, not because it is often needed.
ITWeb/스크랩 2008. 3. 5. 15:59
1. Web Service
http://en.wikipedia.org/wiki/Web_service
A Web service (also Web Service) is defined by the W3C as "a software system designed to support interoperable Machine to Machine interaction over a network." Web services are frequently just Web APIs that can be accessed over a network, such as the Internet, and executed on a remote system hosting the requested services.
The W3C Web service definition encompasses many different systems, but in common usage the term refers to clients and servers that communicate using XML messages that follow the SOAP standard. Common in both the field and the terminology is the assumption that there is also a machine readable description of the operations supported by the server written in the Web Services Description Language (WSDL). The latter is not a requirement of a SOAP endpoint, but it is a prerequisite for automated client-side code generation in many Java and .NET SOAP frameworks (frameworks such as Spring and Apache CXF being notable exceptions). Some industry organizations, such as the WS-I, mandate both SOAP and WSDL in their definition of a Web service.
2. Web Services Description Language
http://en.wikipedia.org/wiki/Web_Services_Description_Language
The Web Services Description Language (WSDL, pronounced 'wiz-dəl' or spelled out, 'W-S-D-L') is an XML-based language that provides a model for describing Web services.
The current version of the specification is the 2.0; version 1.1 has not been endorsed by the W3C but version 2.0 is a W3C recommendation. [1] WSDL 1.2 was renamed WSDL 2.0 because of its substantial differences from WSDL 1.1. By accepting binding to all the HTTP request methods (not only GET and POST as in version 1.1) WSDL 2.0 specification offers a better support for RESTful web services, much simpler to implement [2][3]. However support for this specification is still poor in software development kits for Web Services which often offer tools only for WSDL 1.1.
The WSDL defines services as collections of network endpoints, or ports. WSDL specification provides an XML format for documents for this purpose. The abstract definition of ports and messages is separated from their concrete use or instance, allowing the reuse of these definitions. A port is defined by associating a network address with a reusable binding, and a collection of ports define a service. Messages are abstract descriptions of the data being exchanged, and port types are abstract collections of supported operations. The concrete protocol and data format specifications for a particular port type constitutes a reusable binding, where the messages and operations are then bound to a concrete network protocol and message format. In this way, WSDL describes the public interface to the web service.
WSDL is often used in combination with SOAP and XML Schema to provide web services over the Internet. A client program connecting to a web service can read the WSDL to determine what functions are available on the server. Any special datatypes used are embedded in the WSDL file in the form of XML Schema. The client can then use SOAP to actually call one of the functions listed in the WSDL.
XLang is an extension of the WSDL such that "an XLANG service description is a WSDL service description with an extension element that describes the behavior of the service as a part of a business process" [1].
Resources or services are exposed using WSDL by both Web Services Interoperability (WS-I Basic Profile) and WSRF framework.
ITWeb/스크랩 2008. 2. 21. 09:49
ref. http://www.ibm.com/developerworks/kr/library/dwclm/20070327/?ca=drs-kr
일반적으로 과학과 공학은 목적과 대상에 차이가 있다. 과학의 목적이 현상(phenomena)에 대한 설명과 새로운 현상을 예측하는 이론을 만들어 가는 것이라면, 공학은 과학적 발견과 이론을 이용하여 인간 삶의 질을 향상시키기 위한 인공물을 만드는 것이라 할 수 있다. 이런 점에서 월드와이드웹은 지금까지 공학적 연구개발의 대상이었지만, 최근 팀 버너스 리를 포함한 몇몇 연구자들이 웹을 과학의 대상으로 새로운 정체성을 만들어 가고 있다.
'웹 사이언스(web science)'의 탄생은 '인지과학'과 같은 융합학문과 비견될 수 있을 것이다. 인지과학이란 학문은 인간의 인지적 현상에 대해 연구하기 위해 전산학, 심리학, 언어학, 철학, 신경과학과 같은 다양한 학문적 방법론을 통합적으로 수용하면서 탄생했다. 웹 사이언스는 웹 자체와 웹을 매개로 이루어지는 다양한 현상에 대해 연구하기 위하여 여러 분야의 학문이 학제적으로 결합되는 것을 의미한다. 웹과 관련한 현상이 워낙 광범하고 공학적 연구와도 밀접히 연관되어 있어서 웹 사이언스는 인지과학보다 더 넓은 스펙트럼의 학문적 융합이 요구될 것이다.
예컨대 언어학, 논리학, 인지심리학, 인공지능과 같은 학문은 시맨틱 웹의 중요한 연구주제인 웹에서의 지식 표현과 의미 전달에 대해 이론적 기반을 제공할 것이다.
사회적 정보 공간(social information space)인 웹의 구조적 복잡성이 늘어날수록 웹 토폴로지(web topology)를 설명하기 위한 수학과 물리학적 모델에 대한 연구도 필요하다. 웹을 통한 지식 공유와 커뮤니케이션은 웹 인식론과 언론정보학의 연구 대상이 될 것이다. 웹에서의 사회현상을 설명하는 사회학자가 필요하며, 미래의 역사학자는 구글의 방대한 자료를 통해 연구하게 될 것이다. 웹 정치학은 웹을 통해 이루어지는 정치적 현상을 연구하고, 법학자는 웹에서의 지적재산권, 사생활, 보안과 관련한 다양한 문제점을 해결하려 할 것이다.
웹은 모든 것이 분산되어(decentralized) 있으면서 모든 것이 연결되는(connected) 것을 목표로 한다. 정보자원이 분산될 뿐만 아니라 권위(authority)도 분산되기를 원한다. 전문가의 개념이 무너지고 있고 집단지성과 피어(peer)의 역할이 더욱 중요해지고 있다.
하지만 권위가 분산됨으로 인해 웹에서 신뢰할만한 정보와 그렇지 못한 정보를 구분하기 어렵게 되었다. 인간관계에서 합리적이고 논리적인 설명은 신뢰의 중요한 근거가 된다. 마찬가지로 신뢰의 웹(web of trust)을 구현하기 위해서도 정보자원 간의 논리적 연결성이 표현되어야 하며, 그 결과로 제시되는 정보에 대한 추론 과정이 논리적으로 증명될 수 있어야 한다. 이러한 정보표현의 합리성과 논리성이 바로 시맨틱 웹 기술이 목표로 삼고 있는 바다.
시맨틱 웹의 자동화된 지식표현 기술 외에도 웹에서의 윤리 문제를 다루는 윤리철학과 법학은 신뢰의 웹을 구현하기 위한 웹 사이언스의 중요한 학문적 요소가 된다.
인공지능의 연구 분야 중 의무논리(deontic logic)란 분야가 있다. 금지, 허용, 의무와 같은 인간행위의 윤리적이고 법적인 부분을 전산언어로 표현하여 에이전트 프로그램으로 구현하는 방법을 연구하는 분야다. 최근 의무논리는 전자상거래나 로봇 에이전트의 행위를 모델링하는 데 응용되고 있고, 복잡한 사회적 네트워크(social network)에서 정보 보안 및 사생활과 관련한 신뢰의 웹을 구현하는 데 사용될 수 있을 것이다.
웹은 정보 간 연결뿐만 아니라 사람들 간의 사회적 연결을 이루게 하는 기술이다. 정보자원 간의 의미적 연결성과 사회적 네트워크를 위한 의미적 정보공간을 만들어가는 것이 바로 Semantic Web 2.0 기술이다. 정보 검색 및 추천, 사람들 간의 커뮤니케이션이 이루어지는 공간인 웹에서 연결 구조를 분석하여 보여주는 그래프 이론은 웹 사이언스에서 매우 중요한 역할을 할 수 있다. 정보와 사람들 사이의 연결을 수학의 그래프 이론으로 분석함으로써 더 효율적으로 정보를 검색하고 인적 관계지도(social path)를 찾는 데 도움을 줄 것이다. 관심분야가 비슷한 사람들을 찾아 새로운 커뮤니티를 형성할 수 있는 일종의 사이버 지도를 그릴 수 있는 기술도 연구되고 있다.
중앙 집중적 정부도 권력도 없는 웹은 자율적으로 움직이는 거대한 네트워크 시스템이다. 웹에 연결된 각 사람의 행위는 반드시 합리적이라 할 수 없지만 시스템으로서 웹이 만들어 내는 행위는 매우 합리적(rational)이고 사회과학적으로 흥미로운 분석 대상이다. ‘뷰티풀 마인드’란 유명한 영화의 주인공인 존 내시(John Nash)가 큰 업적을 이룬 게임이론(game theory)은 웹이란 거대 시스템의 행위를 분석하는 데 좋은 연구 방법론이 될 수 있다.
우리는 엄청나게 큰 코끼리의 작은 부분만을 만지고 코끼리의 전체 모양을 상상하는 장님과 같다. 진짜 코끼리의 모습을 알 수 있는 방법은 장님들이 각자의 한계를 인정하고 함께 마음을 열고 대화를 하는 것이다. 시맨틱 웹이건 AI건, 어떤 기술도 모든 것을 이룰 수 없다. 할 수 있는 것과 할 수 없는 것을 분명하게 인식하고 함께 협력할 때 기술과 학문의 진보가 이뤄질 수 있다.
ITWeb/스크랩 2008. 2. 21. 09:48
ref. http://www.ibm.com/developerworks/kr/library/dwclm/20070220/?ca=drs-kr
현재 웹 기술 분야에서 큰 주목을 받고 있는 두 가지 키워드가 바로 Semantic Web과 Web 2.0이다. 그러나 지금 이 두 기술 주제를 접근하는 방식에는 약간의 문제가 있다.
차세대 웹 기술로 자주 거론되면서 인터넷 세상을 똑똑한 인공지능 세상으로 뒤바꿀 것 같았던 Semantic Web 기술은 범인들로서는 접근하기 어려운 상아탑에 숨어 있는 느낌이 든다. 웹을 기반으로 한 IT 거품이 허상으로 사라지고 난 뒤 새로운 웹 경제와 문화를 만들어 갈 진정한 차세대 웹 기술일 것 같았던 Web 2.0은 개념과 해석만 무성하고 기술의 알맹이가 없는 느낌이다.
이 두 기술 주제를 결합한 ‘Semantic Web 2.0’이 추구하는 열린 정보공간에서 가능한 일이 무엇일까?
‘Semantic Web 2.0’의 중요한 응용 분야로서 Semantic Desktop과 Semantic Social Network에 대한 연구 개발이 활발히 진행되고 있다.
Semantic Desktop은 RDF와 URI 표준 기술을 사용하여 워드프로세스를 비롯한 여러 응용 프로그램의 파일들을 관리하는 데 새로운 패러다임으로 제안되고 있다. 사용자의 컴퓨터에 있는 각종 데이터를 의미적으로 연결할 수 있다면 검색과 관리가 엄청나게 편해질 수 있으며, 나아가 다른 사람들과 협업을 하는 데도 매우 효과적일 수 있다. 시맨틱 위키, 시맨틱 이메일 등이 대표적인 예라 할 수 있다.
Social Network는 이미 대표적 사이트로 싸이월드나 마이스페이스(MySpace) 같은 것을 들 수 있다. 최근에 블로그를 사용하는 사람들이 늘어나고 다양한 사회적 인적 네트워크를 위한 사이트가 늘어나면서 온라인 Social Network도 갈수록 복잡한 양상을 띠게 되었다.
Semantic Social Network는 개인들 간의 의미적 연결 관계를 표준화된 FOAF와 같은 온톨로지로 표현함으로써 네트워크 관리가 효과적으로 이루어질 수 있게 하는 기술이다. 관심 분야가 비슷하거나 어떤 특정 상황에 연결되어야 할 사람을 찾아준다거나 할 때 이러한 기술은 사용될 수 있다. Semantic Desktop과 Semantic Social Network는 온라인에서 새로운 형태의 협업과 집단지성을 만들 수 있는 수단이 된다.
아인슈타인과 같은 한 사람의 천재보다 집단의 창의성과 지성이 더 요구되는 복잡한 현대 사회에서 Semantic Web 2.0은 어떤 역할을 할 수 있을 것인가?
창의성에 대한 시스템 이론을 주창한 저명한 학자인 Csiksentmihalyi에 의하면 창의성이란 한 개인의 인지적 활동의 결과(product)라기보다는 사회문화적 프로세스(process)로 설명될 수 있다. 물론 한 개인의 지성이 창의적 작품을 만드는 시발점이 되지만 작품을 평가하는 다른 사회 구성원들과의 상호작용을 통해 더 나은 작품으로 진화 발전되어 가는 것이다.
즉, 지성과 창의성은 시스템의 세 가지 구성요소인 개인(individual), 창의적 활동의 내용이 되는 영역(domain), 그 분야의 커뮤니티(field) 간의 끊임없는 상호작용에 의해 진화되는 과정으로 정의될 수 있다. 지성의 진화가 효과적으로 진행될수록 지식의 체계인 영역 – 수학, 과학 등과 같은 넓은 영역과 Semantic Web과 같은 더 세분화된 영역 – 은 더욱 발전하게 된다. 영역의 발전으로 더 많은 양의 정보가 개인에게 전달되고 이로써 개인 차원의 지성도 확장될 수 있는 것이다.
Semantic Web 2.0은 집단지성의 진화를 위한 공간이 되고 이를 위한 소프트웨어 기술을 제공할 수 있다. Semantic Desktop은 그 분야에 있는 사람들 간의 협업과 정보 공유를 더욱 효과적으로 해 준다. Semantic Social Network을 통해 다양한 새로운 커뮤니티가 형성될 수 있고, 커뮤니티 활동을 효과적일 수 있게 하는 소프트웨어 기술을 통해 집단지성이 진화하면서 지식의 체계인 영역 또한 발전하게 된다.
오픈 플랫폼(open platform)으로서 위키피디어(Wikipedia)는 새로운 출판과 협업 문화의 좋은 모델이 되고 있다. 몇몇 전문가의 지식보다는 다양한 사람이 모여 상호작용을 하면서 끊임없이 콘텐츠를 진화, 발전시킬 수 있는 효과적인 도구를 제공한다면 그것이 바로 Semantic Web 2.0이 할 수 있는 역할이다.
새로운 차원의 디지털 도서관은 양질의 UCC들을 선택적으로 독자들에게 제공할 수 있고 독자로 하여금 도서의 내용을 제공받고 평가할 수 있게 하는 양방향적 시스템으로 발전할 수 있을 것이다. 새로운 차원의 과학 연구 문화에서는 서너 명의 선택된 리뷰어가 논문을 평가해 출판하는 것이 아니라 그 분야의 수많은 사람들로부터 지속적으로 평가와 발전적 피드백이 이루어질 수 있는 것이다.
출판은 일회적이고 소수에 의해 지배당하는 것이 아니라 진화되고 대중에게 열려있는 것이다. 지식의 권위에 대한 평가와 인정은 관심을 갖고 적극적으로 그 분야에 참여하는 다수에 의해 이루어지는 것이다. 오픈소스 소프트웨어 문화는 이미 열린 참여를 지향하는 문화로 정착되었다. 참여하고 내어 놓는 자들은 그만큼의 것을 가져갈 수 있도록 Social Semantic Information Space를 제공해주는 기술이 바로 Semantic Web 2.0인 것이다.
|

