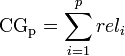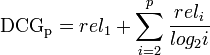MacBook JAVA_HOME 설정.
ITWeb/개발일반 2014. 11. 3. 11:57# JDK6
export JAVA_HOME=`/usr/libexec/java_home -v 1.6`
# JDK7
export JAVA_HOME=`/usr/libexec/java_home -v 1.7`
# JDK8
export JAVA_HOME=`/usr/libexec/java_home -v 1.8`
05-17 03:57
|
MacBook JAVA_HOME 설정.ITWeb/개발일반 2014. 11. 3. 11:57# JDK6 export JAVA_HOME=`/usr/libexec/java_home -v 1.6` # JDK7 export JAVA_HOME=`/usr/libexec/java_home -v 1.7` # JDK8
export JAVA_HOME=`/usr/libexec/java_home -v 1.8` [ElasticSearch] _score 계산 시 IDF 연산은 어떻게 이루어 지나요?Elastic/Elasticsearch 2014. 10. 30. 11:53어제 저희 회사 행사에서 "오픈소스 검색엔진 구축 사례"로 발표를 했었는데요. 저에게 질문 주셨던 것중에 나름 재밌는 질문을 주셨던 내용이 있어서 공유 드립니다. (아마도 질문 주신 분은 elasticsearch 를 사용해 보지 않으셨거나 경험 하신지 얼마 안되신 것 같다는 느낌 이였구요. lucene 은 많이 사용해보신 분 같다는 느낌 이였습니다. ㅎㅎ 제 느낌이니 틀릴수도 있구요.) 질문은 이랬던것 같습니다. - elasticsearch 에서 색인 시에, IDF 값을 Global 하게 쓰기 어려울 텐데 어떻게 사용되는 지에 대한 질문이었습니다 정답은 아래 링크에 나와 있죠. ^^ (shard 별로 이루어 집니다.) http://www.elasticsearch.org/guide/en/elasticsearch/guide/current/relevance-intro.html 우선 TF의 경우 뭐 그냥 term frequency 니까 이건 별 문제 없을 거구요. (기본 per field similarity 입니다.) IDF의 경우는 그럼 어떻게 할까요 인데요???? IDF는 쉽게말해 index 내 전체 문서에서의 term이 포함된 document frequency 가 되는 건데요. 루씬에서는 뭐 당연히 문제가 안되겠지만 es 에서는 shard 라는 개념이 있죠. 즉 하나의 index를 여러개의 shard 로 나눠서 서로 다른 노드에 가지고 있으니 IDF 를 어떻게 계산 할 수 있을지.... 제가 보는 관점은 단순 합니다. - shard 별 document 의 idf 값만 보면 document 의 relevance가 문제일수 있지만, document 의 score 의 경우 tf + idf + field length norm 등 다양한 요소와 함께 계산되기 떄문에 normalized 되었다고 봅니다. 즉 score 값을 신뢰 할 수 있다 입니다. ㅎㅎ 간만에 검색 질문을 주셔서 재밌었습니다. [ElasticSearch] bitset...Elastic/Elasticsearch 2014. 10. 17. 18:25내 블로그에 안남기고 페북에만 남겼내..ㅋㅋ 그냥 지나가다가... 질의 성능 최적화에서 queries vs filters 에 대해 이해하고 사용하고 계실줄로 압니다만, ^^; 요기에 추가로 bitset 에 대해서도 내용이 나오기 때문에 그냥 참고하시라고 링크 던져 봅니다. ^^ filter 가 빠르다라고 이야기 하는 부분에서 bitset에 대한 이해가 없으면 안될것 같아서요. https://lucene.apache.org/core/4_10_1/core/org/apache/lucene/util/OpenBitSet.html 쉽게는 term filter 했을 떄 match 된 term 에 대해서 bitset 을 1로 marking 해 두어 다음에 이 bitset 만 보고 문서를 리턴하게 된다 뭐 그런 이야기 입니다. DCG ...Legacy 2014. 10. 15. 11:17원본 : http://freesearch.pe.kr/archives/1574Discounted Cumulative GainDCG라는 metric은 기존의 precision, recall 기반의 검색엔진 평가 방법으로는 순위에 따른 차별점을 부과하기 힘들다는 판단에 따라 나온 방법이다. Cumulative Gain이는 그냥 n개의 검색 결과의 등급을 모두 합한 값이다. 관련성에 따라 3~0 사이의 값을 가진다고 하면 ideal CG와 현재 CG를 기반으로 절대적인 점수를 도출할 수도 있다. Discounted Cumulative Gain이는 실제 검색 결과 순서에 따른 패널티를 적용한 점수값을 도출한다.
Normalizing DCG위 DCG 점수는 현재 검색엔진의 결과의 상태를 보여준다. 그렇다면 가장 이상적인 검색엔진의 점수로 위 점수를 나누어 주면 정규화된 DCG가 나올 것이다.
개인적으로 랭킹관련 평가를 할때 이 log함수를 많이 쓰고 있는데, log n값의 결과가 0이 되는 시기만 조심하면 랭킹관련 문제에서 아주 요긴하게 쓰일 수 있다. bash for loop...ITWeb/개발일반 2014. 10. 6. 12:17머리가 나빠서 맨날 까먹어요...ㅡ.ㅡ;; 일반적인 bash for loop.. for i in 1 2 3 4 5 do echo $i done start, end 를 가지는 for loop START=1 END=5 for (( i=$START; i<=$END; i++ )) do echo $i done while 문은 그냥 귀찮아서 pass, 필요 하면 구글링에게... ^^; |