|
|
Elastic/Elasticsearch 2014. 2. 7. 10:18
http://www.elasticsearch.org/blog/elasticsearch-hadoop-1-3-m2/
몇 가지 기능 개선이랑 패키지명이 바뀌었내요. 그리고 기존에는 es.host 로 node 하나만 지정 할 수 있었는데 es.nodes 로 바뀐거 보면 병렬 분산 처리를 지원 하는 것 처럼 보이내요.
Elastic/Elasticsearch 2014. 1. 28. 16:47
elasticsearch 에서 어떤식으로 index 와 document 를 분산 시키는지 궁금 하신 분들이 계실걸로 압니다. 뭐 소스 코드 보신 분들은 다 아실 것 같고 보기 귀찮으신 분들을 위해서 짧게 적어 봅니다.
[Index Sharding Route] - index settings 에서 number_of_shards 설정 정보를 이용합니다.
- 그래서 각 node 들에 순서데로 나눠서 할당을 합니다.
[Document Route] - sharding 된 index shard 에 document 를 어떻게 분배 할지 결정을 합니다. - 분배는 hash 알고리즘을 이용합니다. - Math.abs( hash(....) % numberOfShards )
관련 소스는 아래 - org.elasticsearch.cluster.routing 패키지 입니다.
Elastic/Elasticsearch 2014. 1. 23. 15:23
원문 : https://speakerdeck.com/elasticsearch/query-optimization-go-more-faster-better
filters are fast, cached, composable, short-circuit
no score is calculated, only inclusion / exclusion
term, terms, range query 에 대해 term, terms, range filter 로 대체 하여 사용.
[from]
{
"query" : {
"term" : {
"field" : "value"
}
}
}
[to]
{
"query" : {
"filtered" : {
"query" : {
"match_all" : {}
},
"filter" : {
"term" : {
"field" : "value"
}
}
}
}
}
Top level filter is slow.
{
"query" : { … },
"filter" : { … }
}
Don't use this unless you need it
(only useful with facets)
Using Count (더 빠름)
[from]
/{index}/_search
{
"query" : { … },
"size" : 0
}
[to]
/{index}/_search?search_type=count
{
"query" : { … }
}
Rescore API
1. Query/filter to quickly find top N results
2. Rescore with complex logic to find top 10
Do not EVER use these in a search script.
[to]
_source.field _fields.field
두개 항목은 disk 에서 읽기 때문에 느립니다.
[from] in-memory field data 를 읽기 때문에 빠릅니다.
Elastic/Elasticsearch 2014. 1. 22. 17:25
참고 URL : http://www.elasticsearch.org/overview/logstash/
data.json 파일에 라인 단위로 로그가 쌓이게 되면 이벤트를 받아서 elasticsearch 로 저장 하게 됩니다. json format 이기 떄문에 당연히 field:value 형태로 저장됩니다.
[실행] java -jar logstash-1.3.3-flatjar.jar agent -f logstash-elasticsearch.conf -v
[실행 + 웹UI] java -jar logstash-1.3.3-flatjar.jar agent -f logstash-elasticsearch.conf -v -- web
※ 이렇게 실행 하면 kibana 를 별도로 설치 하지 않으셔도 됩니다. ※ 샘플 데쉬보드 : http://192.168.0.120:9292/index.html#/dashboard/file/guided.json
[logstash-elasticsearch.conf]
input {
file {
path => "/server/app/logstash/log/data.json"
codec => json
start_position => "beginning"
}
}
output {
stdout { debug => true debug_format => "json"}
elasticsearch_http {
host => "192.168.0.120"
port => 9200
}
}
※ output 부분에서 stdout 에 설정된 값은 -v 옵션 주고 실행시켰을 때 디버그 메시지를 찍기 위해서 설정 된 것입니다.
[input file]
http://logstash.net/docs/1.3.3/inputs/file input {
file {
add_field => ... # hash (optional), default: {}
codec => ... # codec (optional), default: "plain"
debug => ... # boolean (optional), default: false
discover_interval => ... # number (optional), default: 15
exclude => ... # array (optional)
path => ... # array (required)
sincedb_path => ... # string (optional)
sincedb_write_interval => ... # number (optional), default: 15
start_position => ... # string, one of ["beginning", "end"] (optional), default: "end"
stat_interval => ... # number (optional), default: 1
tags => ... # array (optional)
type => ... # string (optional)
}
}
[output elasticsearch_http] http://logstash.net/docs/13.3/outputs/elasticsearch_http output {
elasticsearch_http {
codec => ... # codec (optional), default: "plain"
document_id => ... # string (optional), default: nil
flush_size => ... # number (optional), default: 100
host => ... # string (required)
idle_flush_time => ... # number (optional), default: 1
index => ... # string (optional), default: "logstash-%{+YYYY.MM.dd}"
index_type => ... # string (optional)
manage_template => ... # boolean (optional), default: true
password => ... # password (optional), default: nil
port => ... # number (optional), default: 9200
replication => ... # string, one of ["async", "sync"] (optional), default: "sync"
template => ... # a valid filesystem path (optional)
template_name => ... # string (optional), default: "logstash"
template_overwrite => ... # boolean (optional), default: false
user => ... # string (optional), default: nil
workers => ... # number (optional), default: 1
}
}
output plugin 에 보면 elasticsearch 도 있는데 이건 테스트 해보니 이미 설치되어 실행 중인 elasticsearch 와 연동하는데 문제가 있는 것 같습니다. 문서 보면 되는 것 처럼 나와 있는데 일단 실패해서 elasticsearch_http 를 이용했습니다.
Elastic/Elasticsearch 2014. 1. 22. 10:42
그냥 elasticsearch.org 블로그 들어가 보시면 있는 내용입니다. 관심 있는 분들은 벌써 아실 내용이긴 한데 그냥 소개해 봅니다.
January 21, 2014
이건 원래도 있던 기능이긴 했는데 그닥 유용하다고 생각 하지 않았습니다. 이번에 나온건 실제 유용하게 사용할 수 있겠더라구요. 일단 지원 하는 repository 를 보면.
Currently, we support file system, S3, Azure and HDFS repositories.
백업 및 복구용으로 활용하세요.
January 20, 2014
간단하게 소개 하면 index 에 대한 disk 용량 관리를 해주는 도구라고 보시면 됩니다. 아마도 logstash 를 사용하시는 분들에게 필요한 도구 일 것 같구요. cron 에 등록해 놓고 사용 하시면 됩니다.
[옵션] $ curator.py -h
usage: curator.py [-h] [-v] [--host HOST] [--port PORT] [-t TIMEOUT]
[-p PREFIX] [-s SEPARATOR] [-C CURATION_STYLE]
[-T TIME_UNIT] [-d DELETE_OLDER] [-c CLOSE_OLDER]
[-b BLOOM_OLDER] [-g DISK_SPACE]
[--max_num_segments MAX_NUM_SEGMENTS] [-o OPTIMIZE] [-n]
[-D] [-l LOG_FILE]
Curator for Elasticsearch indices. Can delete (by space or time), close,
disable bloom filters and optimize (forceMerge) your indices.
optional arguments:
-h, --help show this help message and exit
-v, --version show program version number and exit
--host HOST Elasticsearch host. Default: localhost
--port PORT Elasticsearch port. Default: 9200
-t TIMEOUT, --timeout TIMEOUT
Elasticsearch timeout. Default: 30
-p PREFIX, --prefix PREFIX
Prefix for the indices. Indices that do not have this
prefix are skipped. Default: logstash-
-s SEPARATOR, --separator SEPARATOR
Time unit separator. Default: .
-C CURATION_STYLE, --curation-style CURATION_STYLE
Curate indices by [time, space] Default: time
-T TIME_UNIT, --time-unit TIME_UNIT
Unit of time to reckon by: [days, hours] Default: days
-d DELETE_OLDER, --delete DELETE_OLDER
Delete indices older than n TIME_UNITs.
-c CLOSE_OLDER, --close CLOSE_OLDER
Close indices older than n TIME_UNITs.
-b BLOOM_OLDER, --bloom BLOOM_OLDER
Disable bloom filter for indices older than n
TIME_UNITs.
-g DISK_SPACE, --disk-space DISK_SPACE
Delete indices beyond n GIGABYTES.
--max_num_segments MAX_NUM_SEGMENTS
Maximum number of segments, post-optimize. Default: 2
-o OPTIMIZE, --optimize OPTIMIZE
Optimize (Lucene forceMerge) indices older than n
TIME_UNITs. Must increase timeout to stay connected
throughout optimize operation, recommend no less than
3600.
-n, --dry-run If true, does not perform any changes to the
Elasticsearch indices.
-D, --debug Debug mode
-l LOG_FILE, --logfile LOG_FILE
log file
Elastic/Elasticsearch 2014. 1. 21. 16:09
elasticsearch 에서 클러스터 설정과 노드간의 통신에 대한 기본 정책을 설정 하는 역할을 discovery 라 보면 됩니다. 그럼 원문을 아래 살펴 볼까요? 원문 path : /elasticsearch/docs/reference/modules/discovery/zen.asciidoc ec2 참고 : /elasticsearch/docs/reference/modules/discovery/ec2.asciidoc
[[modules-discovery-zen]]
=== Zen Discovery
The zen discovery is the built in discovery module for elasticsearch and
the default. It provides both multicast and unicast discovery as well
being easily extended to support cloud environments. ▶ multicast, unicast, cloud 환경을 지원 하내요.
The zen discovery is integrated with other modules, for example, all
communication between nodes is done using the
<<modules-transport,transport>> module.
It is separated into several sub modules, which are explained below:
[float]
[[ping]]
==== Ping
This is the process where a node uses the discovery mechanisms to find
other nodes. There is support for both multicast and unicast based
discovery (can be used in conjunction as well). ▶ 노드를 찾거나 찔러 볼때 사용하내요.
[float]
[[multicast]]
===== Multicast
▶ 이건 사실 추천 하고 있지 않습니다. 불필요한 트래픽을 양산 한다고 해서요..
Multicast ping discovery of other nodes is done by sending one or more
multicast requests where existing nodes that exists will receive and
respond to. It provides the following settings with the
`discovery.zen.ping.multicast` prefix:
[cols="<,<",options="header",]
|=======================================================================
|Setting |Description
|`group` |The group address to use. Defaults to `224.2.2.4`.
|`port` |The port to use. Defaults to `54328`.
|`ttl` |The ttl of the multicast message. Defaults to `3`.
|`address` |The address to bind to, defaults to `null` which means it
will bind to all available network interfaces.
|=======================================================================
Multicast can be disabled by setting `multicast.enabled` to `false`.
[float]
[[unicast]]
===== Unicast
▶ 이걸 추천 하고 있죠.. ^^ 딱 보시면 아시겠지만 불특정 다수(?)에 보내는 multicast 방식과 다르게 지정한 노드로만 통신 하게 되니까 효율적이겠죠.
The unicast discovery allows to perform the discovery when multicast is
not enabled. It basically requires a list of hosts to use that will act
as gossip routers. It provides the following settings with the
`discovery.zen.ping.unicast` prefix:
[cols="<,<",options="header",]
|=======================================================================
|Setting |Description
|`hosts` |Either an array setting or a comma delimited setting. Each
value is either in the form of `host:port`, or in the form of
`host[port1-port2]`.
|=======================================================================
The unicast discovery uses the
<<modules-transport,transport>> module to
perform the discovery.
[float]
[[master-election]]
==== Master Election
▶ 이건 master node 가 장애가 났을 때 node.master: true 로 설정 되어 있는 노드들에서 선출 하는 기능 입니다.
▶ 전체 코디네이션 역할을 마스터 노드가 하기 떄문에 중요한 기능입니다.
As part of the initial ping process a master of the cluster is either
elected or joined to. This is done automatically. The
`discovery.zen.ping_timeout` (which defaults to `3s`) allows to
configure the election to handle cases of slow or congested networks
(higher values assure less chance of failure). Note, this setting was
changed from 0.15.1 onwards, prior it was called
`discovery.zen.initial_ping_timeout`.
Nodes can be excluded from becoming a master by setting `node.master` to
`false`. Note, once a node is a client node (`node.client` set to
`true`), it will not be allowed to become a master (`node.master` is
automatically set to `false`).
The `discovery.zen.minimum_master_nodes` allows to control the minimum
number of master eligible nodes a node should "see" in order to operate
within the cluster. Its recommended to set it to a higher value than 1
when running more than 2 nodes in the cluster.
▶ brain split 즉 네트웍 상에서 발생 가능한 단절로 인하여 데이터가 깨졌을 때를 방지 하기 위해 최소한 마스터 노드 역할을 수행 할 수 있는 노드를 2개 이상 설정 하라는 내용입니다.
[float]
[[fault-detection]]
==== Fault Detection
▶ 이건 뭐 그냥 봐도 아시겠죠..
There are two fault detection processes running. The first is by the
master, to ping all the other nodes in the cluster and verify that they
are alive. And on the other end, each node pings to master to verify if
its still alive or an election process needs to be initiated.
The following settings control the fault detection process using the
`discovery.zen.fd` prefix:
[cols="<,<",options="header",]
|=======================================================================
|Setting |Description
|`ping_interval` |How often a node gets pinged. Defaults to `1s`.
|`ping_timeout` |How long to wait for a ping response, defaults to
`30s`.
|`ping_retries` |How many ping failures / timeouts cause a node to be
considered failed. Defaults to `3`.
|=======================================================================
[float]
==== External Multicast
The multicast discovery also supports external multicast requests to
discover nodes. The external client can send a request to the multicast
IP/group and port, in the form of:
[source,js]
--------------------------------------------------
{
"request" : {
"cluster_name": "test_cluster"
}
}
--------------------------------------------------
And the response will be similar to node info response (with node level
information only, including transport/http addresses, and node
attributes):
[source,js]
--------------------------------------------------
{
"response" : {
"cluster_name" : "test_cluster",
"transport_address" : "...",
"http_address" : "...",
"attributes" : {
"..."
}
}
}
--------------------------------------------------
Note, it can still be enabled, with disabled internal multicast
discovery, but still have external discovery working by keeping
`discovery.zen.ping.multicast.enabled` set to `true` (the default), but,
setting `discovery.zen.ping.multicast.ping.enabled` to `false`.
이상 살펴 봤습니다. 뭐 별거 없죠.. ^^
[세 줄 요약] 1. unicast 를 사용해라. 2. multicast 는 disable 해라. 3. minimum master node 는 2개 이상 설정해라.
Elastic/Elasticsearch 2014. 1. 17. 10:55
분명 글을 작성했던 것 같은데 보이질 않내요. 그래서 다시 올려 봅니다. ㅡ.ㅡ;;
[start.sh] #!/bin/bash
export ES_HEAP_SIZE=256m
export ES_HEAP_NEWSIZE=128m
export JAVA_OPT="-server -XX:+AggressiveOpts -XX:UseCompressedOops -XX:MaxDirectMemorySize -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly"
ES=/home/es/app/elasticsearch
$ES/bin/elasticsearch -p $ES/bin/es.pid -Des.config=$ES_NODE/config/elasticsearch.yml -Djava.net.preferIPv4Stack=true -Des.max-open-files=true > /dev/null 2>&1 &
[stop.sh] #!/bin/bash
ES=/home/es/app/elasticsearch
/bin/kill `cat < $ES/bin/es.pid`
Elastic/Elasticsearch 2014. 1. 15. 15:48
field type mapping 할 때 매번 작성하기 귀찮아서 그냥 참고용으로 가장 많이 쓰는 옵션만 적어 봅니다.
- number type index not_analyzed
{"type" : "long", "store" : "no", "index" : "not_analyzed", "index_options" : "docs", "ignore_malformed" : true, "include_in_all" : false}
- number type index no
{"type" : "long", "store" : "yes", "index" : "no", "ignore_malformed" : true, "include_in_all" : false}
- string type index analyzed
{"type" : "string", "store" : "no", "index" : "analyzed", "omit_norms" : false, "index_options" : "offsets", "term_vector" : "with_positions_offsets", "include_in_all" : false}
- string type index not_analyzed
{"type" : "string", "store" : "no", "index" : "not_analyzed", "omit_norms" : true, "index_options" : "docs", "include_in_all" : false}
- string type index no
{"type" : "string", "store" : "yes", "index" : "no", "include_in_all" : false}
- boolean type index yes
{"type" : "boolean", "store" : "yes", "include_in_all" : false}
- boolean type index no
{"type" : "boolean", "store" : "yes", "index" : "no", "include_in_all" : false}
참고 URL : http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/mapping-core-types.html
Elastic/Elasticsearch 2014. 1. 14. 17:43
field 가 number type 인 경우 이 설정을 어떻게 해주느냐에 따라 검색 성능에 영향을 줄 수 있습니다. 계산식은 아래 보는 바와 같습니다.
업데이트 : http://lucene.apache.org/core/4_6_0/core/org/apache/lucene/search/NumericRangeQuery.html
원문은 : http://lucene.apache.org/core/4_3_0/core/org/apache/lucene/search/NumericRangeQuery.html#precisionStepDesc
Precision StepYou can choose any precisionStep when encoding values. Lower step values mean more precisions and so more terms in index (and index gets larger). The number of indexed terms per value is (those are generated by NumericTokenStream): indexedTermsPerValue = ceil(bitsPerValue / precisionStep) As the lower precision terms are shared by many values, the additional terms only slightly grow the term dictionary (approx. 7% for precisionStep=4), but have a larger impact on the postings (the postings file will have more entries, as every document is linked to indexedTermsPerValue terms instead of one). The formula to estimate the growth of the term dictionary in comparison to one term per value: 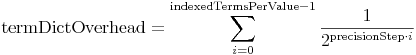 On the other hand, if the precisionStep is smaller, the maximum number of terms to match reduces, which optimizes query speed. The formula to calculate the maximum number of terms that will be visited while executing the query is: ![\mathrm{maxQueryTerms} = \left[ \left( \mathrm{indexedTermsPerValue} - 1 \right) \cdot \left(2^\mathrm{precisionStep} - 1 \right) \cdot 2 \right] + \left( 2^\mathrm{precisionStep} - 1 \right)](http://lucene.apache.org/core/4_3_0/core/org/apache/lucene/search/doc-files/nrq-formula-2.png)
int 형 field 일 경우 4 bytes = 32 bits 로 indexedTermsPerValue = ceil(42 / 4) maxQueryTerms = [ ( 8 - 1 ) * (16 - 1 ) * 2 ] + (16 - 1 ) = 7 * 15 * 2 + 15 = 225
Elastic/Elasticsearch 2014. 1. 14. 17:34
참고글 : http://stackoverflow.com/questions/15019821/what-differents-between-master-node-gateway-and-other-node-gateway-in-elasticsea 참고 하시라고 올려 봅니다.
[원문]
The master node is the same as any other node in the cluster, except that it has been elected to be the master. It is responsible for coordinating any cluster-wide changes, such as
as the addition or removal of a node, creation, deletion or change of
state (ie open/close) of an index, and the allocation of shards to
nodes. When any of these changes occur, the "cluster state" is updated
by the master and published to all other nodes in the cluster. It is the
only node that may publish a new cluster state. The tasks that a master performs are lightweight. Any tasks that deal
with data (eg indexing, searching etc) do not need to involve the
master. If you choose to run the master as a non-data node (ie a node
that acts as master and as a router, but doesn't contain any data) then
the master can run happily on a smallish box. A node is allowed to become a master if it is marked as "master
eligible" (which all nodes are by default). If the current master goes
down, a new master will be elected by the cluster. An important configuration option in your cluster is minimum_master_nodes.
This specifies the number of "master eligible" nodes that a node must
be able to see in order to be part of a cluster. Its purpose is to
avoid "split brain" ie having the cluster separate into two clusters,
both of which think that they are functioning correctly. For instance, if you have 3 nodes, all of which are master eligible, and set minimum_master_nodes
to 1, then if the third node is separated from the other two it, it
still sees one master-eligible node (itself) and thinks that it can form
a cluster by itself. Instead, set minimum_master_nodes to 2 in this case
(number of nodes / 2 + 1), then if the third node separates, it won't
see enough master nodes, and thus won't form a cluster by itself. It
will keep trying to join the original cluster. While Elasticsearch tries very hard to choose the correct defaults, minimum_master_nodes
is impossible to guess, as it has no way of knowing how many nodes you
intend to run. This is something you must configure yourself.
[구글 번역] 마스터 노드 는마스터로 선출 되었음을 제외하고 ,클러스터의 다른 노드 와 동일하다.
|

