|
|
Elastic/Elasticsearch 2014. 1. 15. 15:48
field type mapping 할 때 매번 작성하기 귀찮아서 그냥 참고용으로 가장 많이 쓰는 옵션만 적어 봅니다.
- number type index not_analyzed
{"type" : "long", "store" : "no", "index" : "not_analyzed", "index_options" : "docs", "ignore_malformed" : true, "include_in_all" : false}
- number type index no
{"type" : "long", "store" : "yes", "index" : "no", "ignore_malformed" : true, "include_in_all" : false}
- string type index analyzed
{"type" : "string", "store" : "no", "index" : "analyzed", "omit_norms" : false, "index_options" : "offsets", "term_vector" : "with_positions_offsets", "include_in_all" : false}
- string type index not_analyzed
{"type" : "string", "store" : "no", "index" : "not_analyzed", "omit_norms" : true, "index_options" : "docs", "include_in_all" : false}
- string type index no
{"type" : "string", "store" : "yes", "index" : "no", "include_in_all" : false}
- boolean type index yes
{"type" : "boolean", "store" : "yes", "include_in_all" : false}
- boolean type index no
{"type" : "boolean", "store" : "yes", "index" : "no", "include_in_all" : false}
참고 URL : http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/mapping-core-types.html
Elastic/Elasticsearch 2014. 1. 14. 17:43
field 가 number type 인 경우 이 설정을 어떻게 해주느냐에 따라 검색 성능에 영향을 줄 수 있습니다. 계산식은 아래 보는 바와 같습니다.
업데이트 : http://lucene.apache.org/core/4_6_0/core/org/apache/lucene/search/NumericRangeQuery.html
원문은 : http://lucene.apache.org/core/4_3_0/core/org/apache/lucene/search/NumericRangeQuery.html#precisionStepDesc
Precision StepYou can choose any precisionStep when encoding values. Lower step values mean more precisions and so more terms in index (and index gets larger). The number of indexed terms per value is (those are generated by NumericTokenStream): indexedTermsPerValue = ceil(bitsPerValue / precisionStep) As the lower precision terms are shared by many values, the additional terms only slightly grow the term dictionary (approx. 7% for precisionStep=4), but have a larger impact on the postings (the postings file will have more entries, as every document is linked to indexedTermsPerValue terms instead of one). The formula to estimate the growth of the term dictionary in comparison to one term per value: 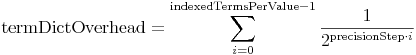 On the other hand, if the precisionStep is smaller, the maximum number of terms to match reduces, which optimizes query speed. The formula to calculate the maximum number of terms that will be visited while executing the query is: ![\mathrm{maxQueryTerms} = \left[ \left( \mathrm{indexedTermsPerValue} - 1 \right) \cdot \left(2^\mathrm{precisionStep} - 1 \right) \cdot 2 \right] + \left( 2^\mathrm{precisionStep} - 1 \right)](http://lucene.apache.org/core/4_3_0/core/org/apache/lucene/search/doc-files/nrq-formula-2.png)
int 형 field 일 경우 4 bytes = 32 bits 로 indexedTermsPerValue = ceil(42 / 4) maxQueryTerms = [ ( 8 - 1 ) * (16 - 1 ) * 2 ] + (16 - 1 ) = 7 * 15 * 2 + 15 = 225
Elastic/Elasticsearch 2014. 1. 14. 17:34
참고글 : http://stackoverflow.com/questions/15019821/what-differents-between-master-node-gateway-and-other-node-gateway-in-elasticsea 참고 하시라고 올려 봅니다.
[원문]
The master node is the same as any other node in the cluster, except that it has been elected to be the master. It is responsible for coordinating any cluster-wide changes, such as
as the addition or removal of a node, creation, deletion or change of
state (ie open/close) of an index, and the allocation of shards to
nodes. When any of these changes occur, the "cluster state" is updated
by the master and published to all other nodes in the cluster. It is the
only node that may publish a new cluster state. The tasks that a master performs are lightweight. Any tasks that deal
with data (eg indexing, searching etc) do not need to involve the
master. If you choose to run the master as a non-data node (ie a node
that acts as master and as a router, but doesn't contain any data) then
the master can run happily on a smallish box. A node is allowed to become a master if it is marked as "master
eligible" (which all nodes are by default). If the current master goes
down, a new master will be elected by the cluster. An important configuration option in your cluster is minimum_master_nodes.
This specifies the number of "master eligible" nodes that a node must
be able to see in order to be part of a cluster. Its purpose is to
avoid "split brain" ie having the cluster separate into two clusters,
both of which think that they are functioning correctly. For instance, if you have 3 nodes, all of which are master eligible, and set minimum_master_nodes
to 1, then if the third node is separated from the other two it, it
still sees one master-eligible node (itself) and thinks that it can form
a cluster by itself. Instead, set minimum_master_nodes to 2 in this case
(number of nodes / 2 + 1), then if the third node separates, it won't
see enough master nodes, and thus won't form a cluster by itself. It
will keep trying to join the original cluster. While Elasticsearch tries very hard to choose the correct defaults, minimum_master_nodes
is impossible to guess, as it has no way of knowing how many nodes you
intend to run. This is something you must configure yourself.
[구글 번역] 마스터 노드 는마스터로 선출 되었음을 제외하고 ,클러스터의 다른 노드 와 동일하다.
Elastic/Elasticsearch 2014. 1. 10. 17:53
공유했다고 생각했는데 아니였나 보내요. 이미 많은 분들이 알고 계실수도 있지만, 반복학습 차원에서.. ^^
https://github.com/bleskes/sense
Sense
A JSON aware developer's interface to ElasticSearch. Comes with handy machinery such as syntax highlighting, autocomplete,
formatting and code folding.
Installation
Sense is installed as a Chrome Extension. Install it from
the Chrome Webstore .
Elastic/Elasticsearch 2014. 1. 8. 18:33
아래 글 참고 http://jjeong.tistory.com/914
이해하기 쉽도록 힌트 몇자 적습니다. 기본 이해는
http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/indices-templates.html 이 문서를 보시면 됩니다.
step 1. template 을 생성 합니다. curl -XPUT localhost:9200/_template/template_1 -d '
{
"template" : "te*",
"settings" : {
"number_of_shards" : 1
},
"mappings" : {
"type1" : {
"_source" : { "enabled" : false }
}
}
}
' 여기서 template : te* 이 의미 하는 것은 index 명입니다.
step 2.
curl -XPUT 'http://localhost:9200/temp/' 이렇게 생성하면 temp 라는 인덱스의 settings/mappings 정보는 template_1 값을 가지게 됩니다.
logstash 예제로 보겠습니다. 아래는 template 생성용 json 입니다. { "template" : "logstash-*", "settings" : { "index.refresh_interval" : "5s", "analysis" : { "analyzer" : { "default" : { "type" : "standard", "stopwords" : "_none_" } } } }, "mappings" : { "_default_" : { "_all" : {"enabled" : true}, "dynamic_templates" : [ { "string_fields" : { "match" : "*", "match_mapping_type" : "string", "mapping" : { "type" : "multi_field", "fields" : { "{name}" : {"type": "string", "index" : "analyzed", "omit_norms" : true, "index_options" : "docs"}, "{name}.raw" : {"type": "string", "index" : "not_analyzed", "ignore_above" : 256} } } } } ], "properties" : { "@version": { "type": "string", "index": "not_analyzed" }, "geoip" : { "type" : "object", "dynamic": true, "path": "full", "properties" : { "location" : { "type" : "geo_point" } } } } } } }
보시면 인덱스 명이 logstash-* 로 시작하는 것들은 이 템플릿을 따르게 됩니다. _all 을 enable 한 이유는 특정 필드에 대해서 동적으로 검색을 지원하기 위해서 라고 보시면 됩니다. 특히 string 필드에 대해서는 검색을 하는 것으로 지정을 하였고, multi_field 구성한 이유는 not_analyzed 로 봐서는 facet 기능이나 sort 등의 다른 기능을 활용하기 위해서 인것으로 보입니다.
그럼 이만... :)
Elastic/Elasticsearch 2014. 1. 8. 12:08
색인 스키마를 json 파일로 만들어 놓고 rest api 로 생성 할 때 유용한 스크립트 입니다. 그냥 제가 사용하기 편할라고 대충 만들어 놓은거랍니다.
#!/bin/bash
size=$#
if [ $size -ne 3 ]; then
echo "Usage: create_index.sh IP:PORT INDICE SCHEME_FILE";
echo "Example: create_index.sh localhost:9200 idx_local schema.json";
exit 0;
fi
serviceUri=$1
indice=$2
schema=$3
curl -XDELETE 'http://'$serviceUri'/'$indice
curl -XPUT 'http://'$serviceUri'/'$indice -d @$schema
Elastic/Elasticsearch 2014. 1. 7. 18:55
색인 스키마 관리를 위해서 템플릿 생성을 할 수 있습니다. 쉽게 접할 수 있는 예제로 logstash 정보가 괜찮아 보여서 공유합니다.
http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/indices-templates.html http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/mapping-root-object-type.html#_dynamic_templates
https://gist.github.com/deverton/2970285 https://github.com/logstash/logstash/blob/v1.3.1/lib/logstash/outputs/elasticsearch/elasticsearch-template.json
{ "template": "logstash-*", "settings" : { "number_of_shards" : 1, "number_of_replicas" : 0, "index" : { "query" : { "default_field" : "@message" }, "store" : { "compress" : { "stored" : true, "tv": true } } } }, "mappings": { "_default_": { "_all": { "enabled": false }, "_source": { "compress": true }, "dynamic_templates": [ { "string_template" : { "match" : "*", "mapping": { "type": "string", "index": "not_analyzed" }, "match_mapping_type" : "string" } } ], "properties" : { "@fields": { "type": "object", "dynamic": true, "path": "full" }, "@message" : { "type" : "string", "index" : "analyzed" }, "@source" : { "type" : "string", "index" : "not_analyzed" }, "@source_host" : { "type" : "string", "index" : "not_analyzed" }, "@source_path" : { "type" : "string", "index" : "not_analyzed" }, "@tags": { "type": "string", "index" : "not_analyzed" }, "@timestamp" : { "type" : "date", "index" : "not_analyzed" }, "@type" : { "type" : "string", "index" : "not_analyzed" } } } } }
{ "template" : "logstash-*", "settings" : { "index.refresh_interval" : "5s", "analysis" : { "analyzer" : { "default" : { "type" : "standard", "stopwords" : "_none_" } } } }, "mappings" : { "_default_" : { "_all" : {"enabled" : true}, "dynamic_templates" : [ { "string_fields" : { "match" : "*", "match_mapping_type" : "string", "mapping" : { "type" : "multi_field", "fields" : { "{name}" : {"type": "string", "index" : "analyzed", "omit_norms" : true, "index_options" : "docs"}, "{name}.raw" : {"type": "string", "index" : "not_analyzed", "ignore_above" : 256} } } } } ], "properties" : { "@version": { "type": "string", "index": "not_analyzed" }, "geoip" : { "type" : "object", "dynamic": true, "path": "full", "properties" : { "location" : { "type" : "geo_point" } } } } } } }
Elastic/Elasticsearch 2014. 1. 7. 18:41
그냥 참고용으로 올려 놓는 것입니다. 각 속성들은 서비스 특성에 맞춰서 설정 하시는게 좋습니다.
http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/indices-update-settings.html http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/indices-put-mapping.html http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/mapping-core-types.html
{
"settings" : {
"number_of_shards" : 5,
"number_of_replicas" : 0,
"index" : {
"refresh_interval" : "1s",
"merge" : {
"policy" : { "segments_per_tier" : 5 }
},
"analysis" : {
"analyzer" : {
"analyzer_standard" : {
"type" : "standard",
"tokenizer" : "whitespace",
"filter" : ["lowercase", "trim"]
},
"analyzer_pattern" : {
"type" : "custom",
"tokenizer" : "tokenizer_pattern",
"filter" : ["lowercase", "trim"]
},
"analyzer_ngram" : {
"type" : "custom",
"tokenizer" : "tokenizer_ngram",
"filter" : ["lowercase", "trim"]
}
},
"tokenizer" : {
"tokenizer_ngram" : {
"type" : "nGram",
"min_gram" : "2",
"max_gram" : "10",
"token_chars": [ "letter", "digit" ]
},
"tokenizer_pattern" : {
"type" : "pattern",
"pattern" : ","
}
}
},
"store" : {
"type" : "mmapfs",
"compress" : {
"stored" : true,
"tv" : true
}
}
}
},
"mappings" : {
"INDICE_TYPE_NAME" : {
"_id" : {
"index" : "not_analyzed",
"path" : "KEY_FIELD_NAME"
},
"_source" : {
"enabled" : "true"
},
"_all" : {
"enabled" : "false"
},
"_boost" : {
"name" : "_boost",
"null_value" : 1.0
},
"analyzer" : "analyzer_standard",
"index_analyzer" : "analyzer_standard",
"search_analyzer" : "analyzer_standard",
"properties" : {
"LONG_KEY_FIELD" : {"type" : "long", "store" : "no", "index" : "not_analyzed", "omit_norms" : true, "index_options" : "docs", "ignore_malformed" : true, "include_in_all" : false},
"STRING_SEARCH_FIELD" : {"type" : "string", "store" : "no", "index" : "analyzed", "omit_norms" : false, "index_options" : "offsets", "term_vector" : "with_positions_offsets", "include_in_all" : false},
"STRING_VIEW_FIELD" : {"type" : "string", "store" : "yes", "index" : "no", "include_in_all" : false},
"INTEGER_KEY_FIELD" : {"type" : "integer", "store" : "no", "index" : "not_analyzed", "omit_norms" : true, "index_options" : "docs", "ignore_malformed" : true, "include_in_all" : false},
"FLOAT_KEY_FIELD" : {"type" : "float", "store" : "no", "index" : "not_analyzed", "omit_norms" : true, "index_options" : "docs", "ignore_malformed" : true, "include_in_all" : false},
"LONG_VIEW_FIELD" : {"type" : "long", "store" : "yes", "index" : "no", "ignore_malformed" : true, "include_in_all" : false},
"STRING_KEY_FIELD" : {"type" : "string", "store" : "no", "index" : "not_analyzed", "omit_norms" : true, "index_options" : "docs", "include_in_all" : false},
"NESTED_KEY_FIELD" : {"type" : "nested",
"properties" : {
"STRING_KEY_FIELD" : {"type" : "string", "store" : "no", "index" : "not_analyzed", "omit_norms" : true, "index_options" : "docs", "include_in_all" : false},
"INTEGER_VIEW_FIELD" : {"type" : "integer", "store" : "yes", "index" : "no", "ignore_malformed" : true, "include_in_all" : false}
}
},
"BOOLEAN_VIEW_FIELD" : {"type" : "boolean", "store" : "yes", "include_in_all" : false},
"BOOLEAN_KEY_FIELD" : {"type" : "boolean", "store" : "no", "index" : "not_analyzed", "omit_norms" : true, "index_options" : "docs", "include_in_all" : false},
"OBJECT_VIEW_FIELD" : {"type" : "object", "dynamic" : true, "store" : "yes", "index" : "no", "include_in_all" : false}
}
}
}
}
Elastic/Elasticsearch 2014. 1. 7. 12:30
http://www.elasticsearch.org/contributing-to-elasticsearch/
elasticsearch checkout 받은 후 코드 수정 또는 빌드를 하고 싶을때 참고 하시면 됩니다. 이전 버전에서는 maven 2.x 에서 되었던 것 같은데 지금은 3.x 가 필요 하내요. run configure 에서 maven 3.x 로 변경 하시고 빌드 하시면 정상적으로 빌드가 됩니다.
위 문서에 나와 있는 것 처럼 Goals 에 아래 옵션을 넣고 빌드 하세요. clean package -DskipTests
Elastic/Elasticsearch 2013. 12. 18. 14:59
뭐 별로 어렵거나 거창하지 않습니다. 자동완성의 경우 오타교정, 사전연동 등등 조합이 필요 하지만 일단 es 에서 제공해 주는 prefix query 를 통해서 아주 쉽게 구현 할 수 있습니다.
[Reference] http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/query-dsl-prefix-query.html
[Test URI]
http://localhost:9200/idx_local/_search?{"query":{"prefix":{"item_name":"나"}}} http://localhost:9200/idx_local/_search?{"query":{"prefix":{"item_name":"나이"}}}
[설명] - name 이라는 문서 필드에 "홍길"로 시작하는 문서를 검색해 줍니다. - name field 는 기본 index:not_analyzed 로 선언 되어 있어야 합니다. - 쇼핑 같은데서 인기검색어 자동완성 또는 검색어 자동완성 이런 용도로 활용 하시면 되겠내요.
|

