[Elastic] IaC 기반의 Cluster 관리
Elastic 2020. 8. 31. 12:40Elastic Stack 은 서비스나 데이터를 다루는 모든 기업에서 사용을 하고 있는 매우 훌륭한 오픈소스 입니다.
기본적으로
- Elasticsearch
- Kibana
- Logstash
- Beats
이 4가지 Stack 을 이야기 하고 있으며,
잘 활용 하실 경우 현존 하는 많은 상용 도구들을 모두 재낄 수 있습니다.
단, 기술 내재화와 역량을 확보 하겠다는 의지가 있을 경우에 한해서 입니다.
제가 지금까지 다니던 회사는 주로 서비스 회사 였기 때문에,
특정 도메인에 필요로 하는 기능 개발과 스타트업 특성에 따른 빠른 개발을 할 수 밖에 없었습니다.
올해 회사를 옮기면서 그 동안 만나 봤던 분들의 어려움을 해결 할 수 있는 방법은 없을까 하고 고민 하다,
Elastic Stack 에 대한 설치 자동화 프로그램을 만들어 보기로 했습니다.
그 결과로 우선 1차 버전을 이야기 해볼까 합니다.
Elasticsearch 는 누구나 쉽게 사용이 가능 합니다.
검색 (IR) 에 대한 지식이나 전문성이 없어도 Elasticsearch 를 도구적으로 설치 하고 사용 하는 데는 별 문제가 없습니다.
그래서 빠른 PoC 작업을 할 수도 있는 것 같습니다.
하지만 클러스터를 구성 하고 이를 운영 하면서 인프라 관점으로 접근 하다 보면 어려움이 생기게 됩니다.
- 사용하고자 하는 부서는 많고,
- 그렇다고 단일 클러스터로 구성해서 사용하라고 제공해 줄 수도 없고,
- 인프라 생성 요청도 해야 하고,
- 설정 및 설치도 해야 하고,
- 문제가 생기면 위 과정을 다시 반복 해야 하고,
- 클러스터 최적화는 또 어떻게 해야 하고,
등등....
요청자와 생성자의 편의를 제공 할 수 있으면 어떨까 싶었습니다.
제가 만들어 본 Application 은 아래 Stack 을 이용해서 개발이 되었습니다.
- Spring Framework
- Terraform
- Ansible
- Docker
- AWS (EC2, S3)
- Elasticsearch
AWS 기반으로 먼저 개발을 진행을 했고 추후 Azure 나 GCP 로도 확장을 할 예정입니다.
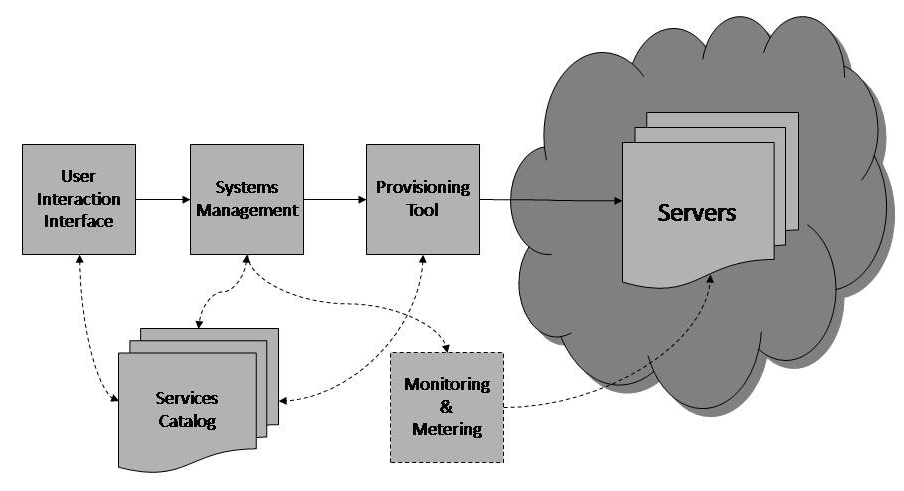
기본 동작 방식은 아래와 같습니다.
1. Application Container
- 인프라 구성을 위한 정보를 설정 하고 설치 파일을 생성 합니다.
- Terraform 관련 파일을 생성 합니다. (setup.tf)
- 생성 될 인스턴스에 설치 할 정보를 설정하고 설치 파일을 생성 합니다.
- Ansible 관련 파일을 생성 합니다. (playbook, inventories, roles)
- 클러스터 구성을 위한 정보를 설정 하고 설치 파일을 생성 합니다.
- Docker Compose 관련 파일을 생성 합니다. (docker-compose.yml)
2. Terraform Backend - S3
- Terraform 을 이용해서 생성한 인스턴스의 정보는 s3 backend 에 저장이 됩니다.
3. Bastion
- 설치 시 보안 관리를 위해 bastion 서버로 ssh tunneling 하여 설치 합니다.
화면 구성은 아래와 같습니다.
그림 1) Terraform 설정 정보와 Elasticsearch Cluster Node Topology 설정 및 실행 화면
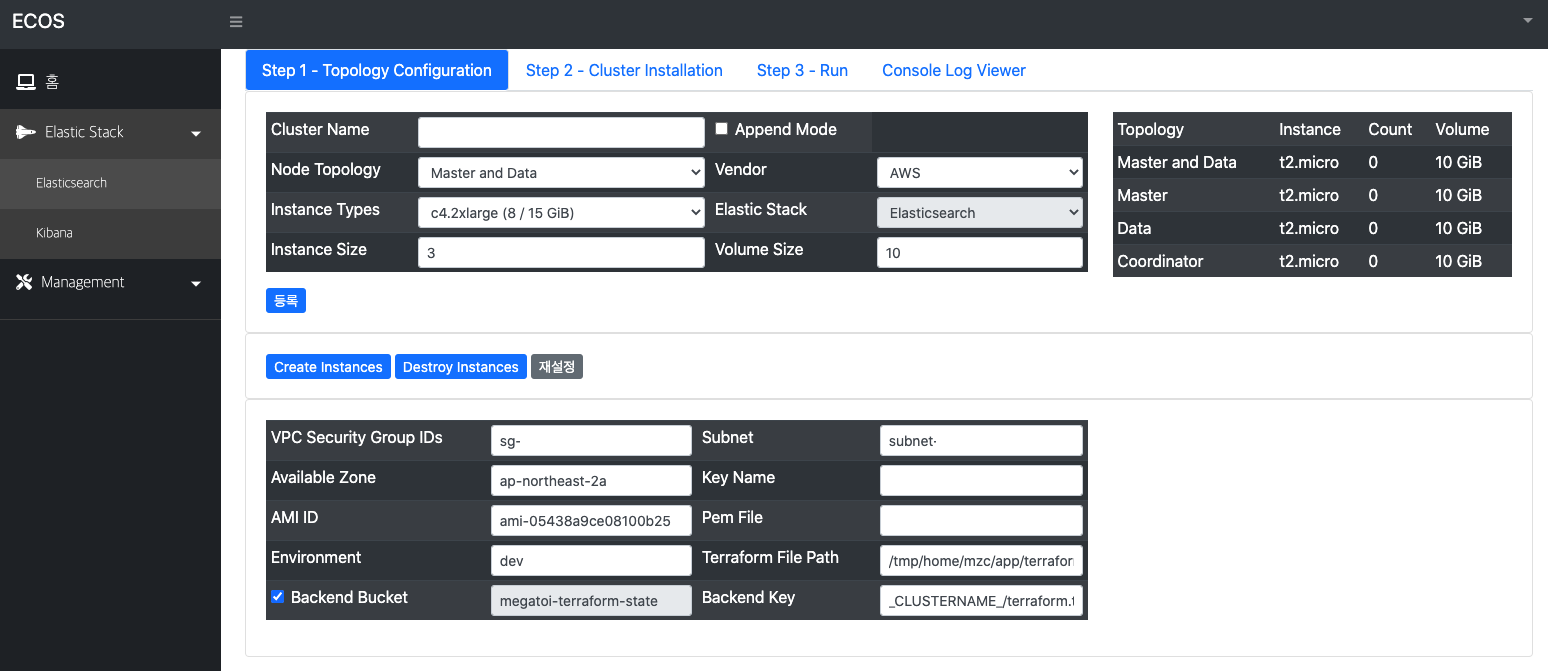
그림 2) Ansible 을 이용한 Node 환경 구성 설정 및 실행 화면
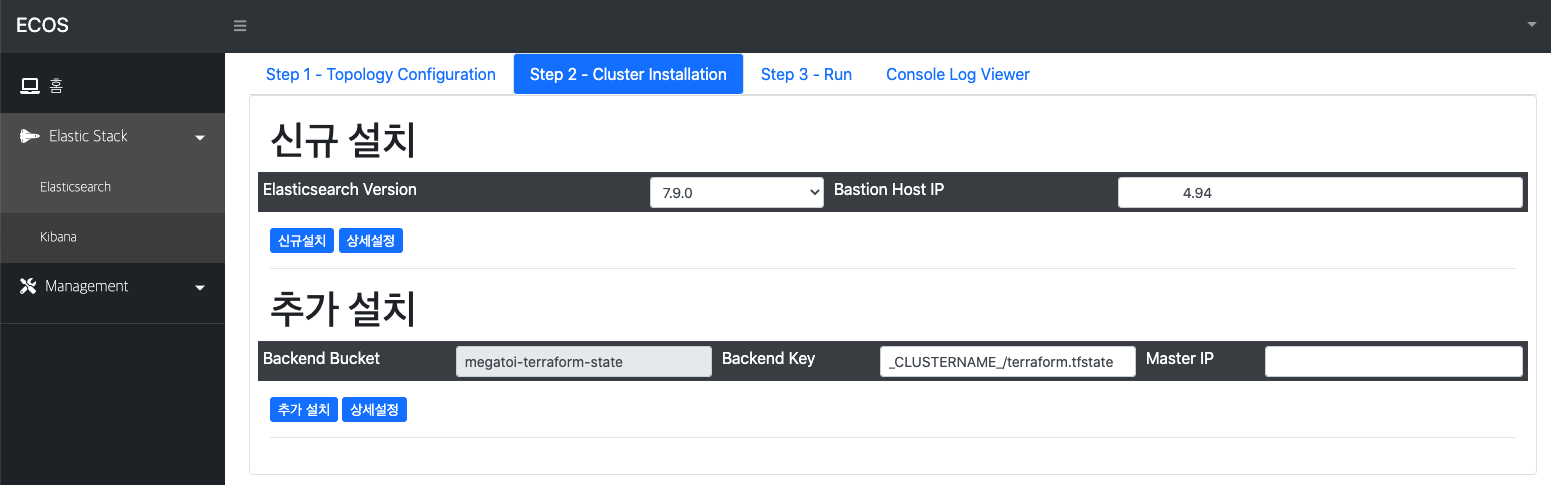
그림 3) Elasticsearch Cluster 실행 화면
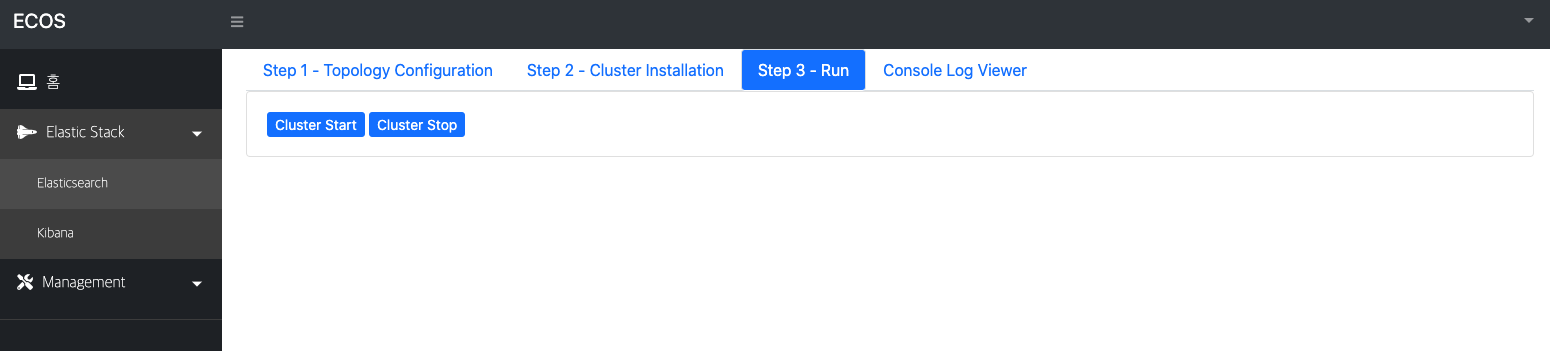
그림 4) 생성 된 Cluster 에 대한 목록 및 관리 화면
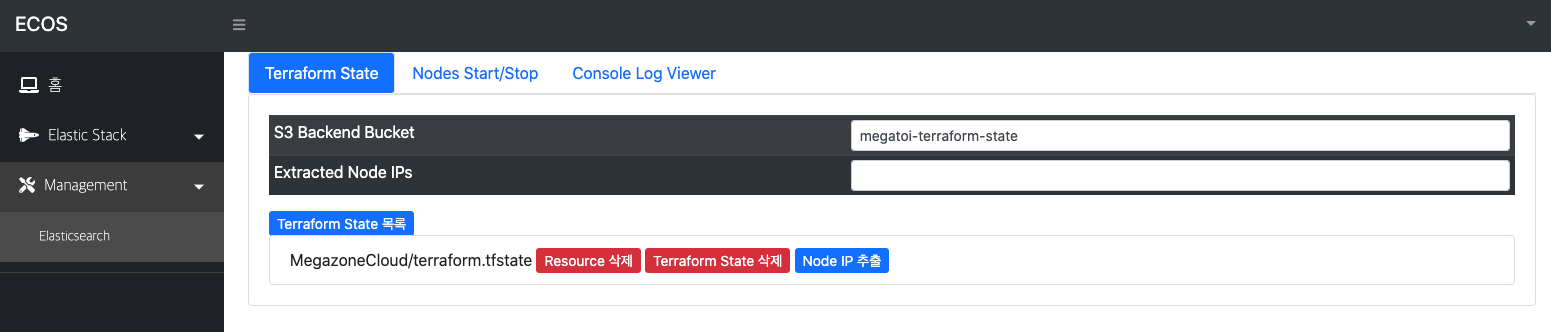
그림 5) 개별 클러스터의 Node 에 대한 관리 화면

만들어진 Application 은 도커 기반으로 개발이 되어 있기 때문에 어떤 환경에서든 실행이 가능 합니다.
가장 기초적인 부분에서 부터 출발한 것으로
- 클러스터 구성 및 설치는 어떻게 해야 하는가?
- 클러스터 구성 시 최적화는 되어 있는가?
- 클러스터를 쉽게 생성 하고 삭제 할 수 있는가?
- 이미 생성된 클러스터에 노드 추가는 어떻게 해야 하는가?
- 개별 노드들에 대한 시작과 중지를 할 수 있는가?
등등...
보시는 바와 같이 클러스터의 생성에서 부터 시작과 중지에 대한 기초 부터 접근을 했습니다.
Elasticsearch 는 크게 3 가지 유형으로 사용을 하게 됩니다.
- 검색
- 저장(색인)
- 분석
위 3 가지 유형을 가지고 Business Domain 별 사용을 하게 되는 것입니다.
- e-Commerce 상품 검색
- SIEM
- Log 및 Data 분석 시스템
등등 ...
이걸 좀 더 고도화 한다고 하면 아래와 같은 서비스들을 쉽게 만들수도 있습니다.
- AWS Elasticsearch Service
- Elastic Cloud - Elasticsearch
회사에서 어떤 전략으로 접근 할 지 아직은 잘 모르겠습니다.
이미 IaC 기반으로 잘 제공 되고 있는 MSP (Elastic, AWS) 가 있는데, 우리가 이것 까지 해야 할까?
이 문제는 뒤로 하고,
Elasticsearch 를 사용하거나 사용하고자 하는 스타트업이 있다면,
누구라도 쉽게 최적화된 클러스터를 생성하고 인프라를 관리 할 수 있도록 제공하면 좋겠다는게 지금 저의 생각 입니다.
오픈소스로 공개를 해도 되고, 컨테이너 이미지를 docker registry 에 등록을 해도 되고 몇 가지 방법이 있겠지만,
정말 이런게 필요한지 부터 고민을 더 해봐야 할 것 같습니다.
아무도 필요로 하지 않는데 계속 투자를 해야 할지도 고민이라서요. ^^;
ECOS(Elastic Cloud Open Stack) Installer 의 기능을 간략하게 요약해 드리면,
- Elasticsearch Cluster 구성을 위한 GUI 환경을 제공 합니다.
- Terraform 기반의 리소스 생성을 제공 합니다.
- Ansible 기반의 설치 및 운영 환경을 제공 합니다.
- Docker 기반의 Cluster 환경 구성 및 관리 기능을 제공 합니다.
- Elasticsearch 설정을 잘 몰라도 됩니다. (이왕이면 알면 좋습니다.)
- Cluster 환경을 최적화 해서 구성해 줍니다.
- Terraform, Ansible, Docker 등에 대해서 잘 몰라도 됩니다. (이왕이면 알면 좋습니다.)
- 리소스를 쉽게 제공하고 회수 할 수 있습니다.
- Cluster 내 Node 추가 기능을 제공 합니다.
ECOS Installer 는 우선
- MZC( Megazone Cloud) 고객사 중
- 기술 내재화를 고민 하고 계신 고객사
를 찾아서 설치 및 기술 이전을 해보려 합니다.
피드백을 받아 가면서 업그레이드를 해보도록 하겠습니다.
감사합니다.