Elastic/Elasticsearch 2020. 6. 19. 11:07
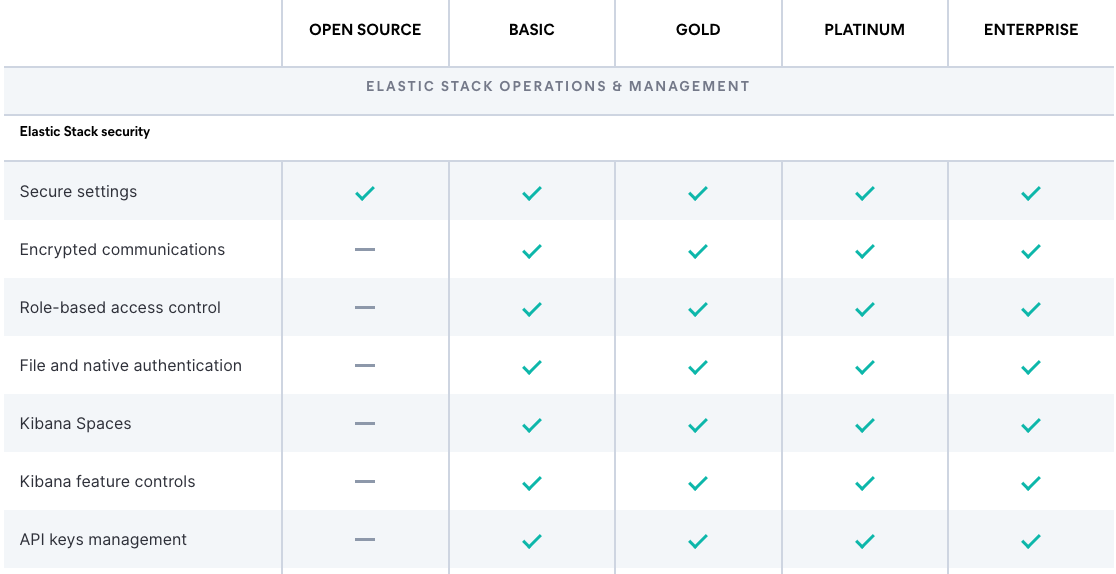
Elastic Stack 이 좋은 이유는 기본 Basic license 까지 사용이 가능 하다는 것입니다.
사실 이것 말고도 엄청 많죠 ㅎㅎ
https://www.elastic.co/subscriptions
딱 API keys management 까지 사용이 됩니다. ㅎㅎㅎ
먼저 사용하기에 앞서서 Elasticsearch 와 Kibana 에 x-pack 사용을 위한 설정을 하셔야 합니다.
[Elasticsearch]
- elasticsearch.yml
xpack.monitoring.enabled: true
xpack.ml.enabled: true
xpack.security.enabled: true
xpack.security.authc.api_key.enabled: true
xpack.security.authc.api_key.hashing.algorithm: "pbkdf2"
xpack.security.authc.api_key.cache.ttl: "1d"
xpack.security.authc.api_key.cache.max_keys: 10000
xpack.security.authc.api_key.cache.hash_algo: "ssha256"위 설정은 기본이기 때문에 환경에 맞게 최적화 하셔야 합니다.
https://www.elastic.co/guide/en/elasticsearch/reference/7.8/security-settings.html#api-key-service-settings
[Kibana]
- kibana.yml
xpack:
security:
enabled: true
encryptionKey: "9c42bff2e04f9b937966bda03e6b5828"
session:
idleTimeout: 600000
audit:
enabled: true
이렇게 설정 한 후 id/password 설정을 하시면 됩니다.
# bin/elasticsearch-setup-passwords interactive
Changed password for user [remote_monitoring_user]
이렇게 설정이 끝나면 kibana 에 접속해서 API key 를 생성 하시면 됩니다.
아래 문서는 생성 시 도움이 되는 문서 입니다.
www.elastic.co/guide/en/elasticsearch/reference/current/security-privileges.html
www.elastic.co/guide/en/elasticsearch/reference/7.7/security-api-put-role.html www.elastic.co/guide/en/elasticsearch/reference/7.7/defining-roles.html www.elastic.co/guide/en/elasticsearch/reference/7.7/security-api-create-api-key.html
Kibana Console 에서 아래와 같이 생성이 가능 합니다.
POST /_security/api_key
{
"name": "team-index-command",
"expiration": "10m",
"role_descriptors": {
"role-team-index-command": {
"cluster": ["all"],
"index": [
{
"names": ["*"],
"privileges": ["all"]
}
]
}
}
}
{
"id" : "87cuynIBjKAXtnkobGgo",
"name" : "team-index-command",
"expiration" : 1592529999478,
"api_key" : "OlVGT_Q8RGq1C_ASHW7pGg"
}생성 이후 사용을 위해서는
- ApiKey 는 id:api_key 를 base64 인코딩 합니다.
base64_encode("87cuynIBjKAXtnkobGgo"+":"+"OlVGT_Q8RGq1C_ASHW7pGg")
==> VGVVOXluSUJHUUdMaHpvcUxDVWo6aUtfSmlEMmdSMy1FUUFpdENCYzF1QQ==curl -H
"Authorization: ApiKey VGVVOXluSUJHUUdMaHpvcUxDVWo6aUtfSmlEMmdSMy1FUUFpdENCYzF1QQ=="
http://localhost:9200/_cluster/health이제 용도와 목적에 맞춰서 API key 를 만들고 사용 하시면 되겠습니다.
Elastic/Logstash 2020. 2. 28. 18:35
전에 그냥 문서 링크만 걸었었는데 혹시 샘플 코드가 필요 하신 분들도 있을 수 있어서 기록해 봅니다.
[config/logstash-csv.conf]
input {
file {
path => ["/Users/henryjeong/Works/poc/elastic/data/*.csv"]
start_position => "beginning"
}
}
filter {
csv {
separator => ","
columns => ["title", "cat1", "cat2", "cat3", "area", "sigungu", "description"]
}
mutate { rename => ["title", "tt"] }
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "csv-%{+YYYY.MM.dd}"
}
}[*.csv]
title,cat1,cat2,cat3,area,sigungu,description
엄마손충무김밥,음식,음식점,한식,경상남도,통영시,"KBS ""1박2일"" 욕지도 복불복에 추천된 충무김밥집이다."
평창동의 봄,음식,음식점,한식,서울,종로구,"평창동의 명소, 평창동 언덕마을에 유럽풍의 아름다운 음식점 & 카페. 1층에는 커피는 물론 계절빙수, 단팥죽, 호박죽, 허브티를 파는 카페, 2층에는 식당이 있다. 2층 식당에서는 평창동 봄만의 특별한 한정식 코스 요리와 웰빙 삼계탕 등의 음식을 선보이고 있다. 3층은 최대 40명수용의 연회룸이 있고, 갤러리 전시와 건강교실도 운영하고 있다. "
음봉가든,음식,음식점,한식,경기도,가평군,"음봉가든 (구, 진짜네집)은 자연산 민물고기만을 고집하는 50년 전통의 진정한 매운탕전문점이다. 주재료로 쓰이고 있는 메기 및 쏘가리, 빠가사리
등은 주인이 직접 낚아 올린 물고기로 매우 신선하며 매운탕 역시 얼큰하고 개운하다. 또한 집앞에서 직접 재배하고 키우는 야채와 채소는 매운탕의 국물맛을 더욱 맛나게 해준다."
대자골토속음식,음식,음식점,한식,경기도,고양시,경기 북부지방에선 국수나 수제비를 넣어 국물을 넉넉하게 만든 음식을 '털레기'라 하는데 이곳은 '미꾸라지털레기'를 주메뉴로 하는 30여년
내력의 경기 북부지방 대표향토음식점이다. 주인이 직접 야채와 채소를 재배하는데 고춧가루까지도 직접 재배한 것을 사용한다고하니 그 사명감이 대단하다 할 수 있겠다. 통미꾸라지매운탕의 옛맛을 찾는 사람이라면 꼭 한번은 들려봐야 전통 맛집이다.
장수촌,음식,음식점,한식,경기도,광명시,"부드러운 닭고기 육질에 구수한 누룽지가 함께 하는 '누룽지삼계탕'. 거기다 잘 익은 김치 한 점 더 한다면 그 어떤 맛도 부러울 것이 없다. 식사메뉴인 '누룽지삼계탕'과 '쟁반막국수', 안주메뉴인 골뱅이무침 메뉴가 전부인 '장수촌'은 경기도 광명의 대표맛집으로 토종닭 선별부터 양념 재료 하나 하나까지 일일이 주인이 직접 선별하는 그 정성과 끈기가 맛의 비결이라 할 수 있겠다."
청기와뼈다귀해장국,음식,음식점,한식,경기도,부천시,"부천 사람이라면 모르는 이 없을 정도로 유명한 집이다. 돼지고기와 국물에서 냄새가 안나 여성이나 어린이들 특히 어르신들 보양식으로
도 입소문이 난 곳인데, 부재료 보다는 뼈다귀로 양을 채우는 그 푸짐함 또한 그 소문이 자자하다. 양질의 돼지 뼈에 사골 국물과 우거지를 넣어 맛을 낸 뼈다귀 해장국. 그 맛을 제대로 만날 수 있는 대표적인 음식점이다. "
일번지,음식,음식점,한식,경기도,성남시,닭요리의 으뜸이라 해도 과언이 아닌 '남한산성 닭죽촌민속마을' 에서 남한산성 등산후 가장 많이 찾는 집 중에 한 집이다. 특히 이집은 닭백숙 이외에 '닭도가니'로도 유명한데 이집의 '도가니'는 소의 도가니를 뜻 하는 것이 아니라 장독대의 '독'에서 유래된 말로 '독'에 밥과 닭과 여러보약재를 넣어 만드는 것으로 그 맛과 영양면에서 닭요리 중에 최고라 할 수 있겠다.
장금이,음식,음식점,한식,경기도,시흥시,"경기도 시흥의 지역특산물 중의 하나가 바로 '연'이다. 연은 수련과에 속하는 다년생 수생식물로 뿌리채소로는 드물게 다량의 비타민과 무기질을 함유하고 있어 최근 건강식 식품원료로 각광받고 있으나 그 효능에 비해 다양한 조리방법이 개발되어 있지 않아 흔히 '연'하면 '연근' 반찬 이외엔 생각나는 것이 없는데, 물왕동 연요리전문점 '장금이'를 찾으면 그렇지 않음을 직접 확인 할 수 있다. 흔치 않은 색다른 한정식을 원한다면 한 번쯤은 꼭 한 번 들러 연밥정식과 연잎수육을 맛 봐야 할 곳이다. "
안성마춤갤러리,음식,음식점,한식,경기도,안성시,경기도 안성의 농산물 브랜드 '안성마춤'을 내세워 만든 고품격 갤러리풍 식당으로 각종 공연과 작품전시회 감상과 동시에 농협에서 직접 운영하는 특등급 안성한우를 맞볼 수 있는 곳으로 유명한 집이다. 특히 안성마춤한우 중에 10%만 생산된다는 슈프림급 한우는 늦어도 하루 전에는 꼭 예약을 해야 그 맛을 볼 수 있다 하여 그 희소성에 더더욱 인기가 높다.
언덕너머매운탕,음식,음식점,한식,경기도,연천군,민물고기 중에 살이 탱탱하고 쫄깃한 맛으로 매운탕 재료 중에 으뜸이라 불리우는 '쏘가리'를 메인메뉴로 자랑하는 이집의 '쏘가리매운탕'은
임진강에서 직접 잡아올린 자연 그대로의 그 담백하고 칼칼한 맛이 일품이라 할 수 있다.보기 좋으라고 개행을 추가 했습니다.
실제 개행 없이 들어 있습니다.
위 데이터는 공공데이터에서 제가 추려 온 데이터 입니다.
위 데이터에서는 Datatype 에 대한 변환을 고민 하지 않아도 되지만 필요한 경우가 있을 수도 있습니다.
공식문서)
https://www.elastic.co/guide/en/logstash/current/plugins-filters-csv.html#plugins-filters-csv-convert
convert
Value type is hash
Default value is {}
Define a set of datatype conversions to be applied to columns. Possible conversions are integer, float, date, date_time, boolean
Example:
filter {
csv {
convert => {
"column1" => "integer"
"column2" => "boolean"
}
}
}keyword 나 text 는 지원 하지 않으며 지원하는 datatype 은 integer, float, date, date_time, boolean 입니다.
csv 파일을 밀어 넣을 때 주의 하셔야 하는 점은)
- input 에서 codec 으로 csv 를 지정 하시게 되면 column 명 지정이 원하는 데로 되지 않습니다.
- filter 에서 처리를 하셔야 정상적으로 column 명이 field 명으로 들어 가게 됩니다.
- input codec csv 와 filter 모두 설정 안하게 되면 그냥 message field 에 row 단위로 들어 가게 됩니다.
mutate { rename => ["title", "tt"] }
- 이건 뭔지 딱 보셔도 아시겠죠?
- column 명을 title 에서 tt 로 변경 해서 field 로 생성 되게 됩니다.
Elastic/Logstash 2019. 11. 7. 15:00
공식 문서에 잘 나와 있습니다.
https://www.elastic.co/guide/en/logstash/current/tuning-logstash.html
https://www.elastic.co/guide/en/logstash/current/performance-tuning.html
기본적으로 아래 두 개 설정만 잘 세팅 하셔도 성능 뽑아 낼 수 있습니다.
pipeline.workers)
이 설정 값은 그냥 기본으로 Core 수 만큼 잡아 주고 시작 하시면 됩니다.
pipeline.batch.size)
Worker thread 가 한 번에 처리 하기 위한 이벤트의 크기 입니다.
결국 Elasticsearch 로 Bulk Request 를 보내기 위한 최적의 크기로 설정 한다고 보시면 됩니다.
이외 더 봐주시면 좋은 건
- CPU
- MEM
- I/O (Disk, Network)
- JVM Heap
Elastic/Logstash 2019. 11. 6. 14:34
문의가 들어 왔습니다.
여러 필드에 대해서 date format 이 다른데 어떻게 적용을 해야 하나요?
그래서 소스코드를 열어 보고 아래와 같이 해보라고 했습니다.
date {
...
}
date {
...
}결국 date {...} 를 필드 별로 선언을 해주면 되는 내용입니다.
공식 문서)
https://www.elastic.co/guide/en/logstash/current/plugins-filters-date.html
Common Options)
https://www.elastic.co/guide/en/logstash/current/plugins-filters-date.html#plugins-filters-date-common-options
Date Filter Configuration Options)
Setting
Input type
Required
locale
string
No
match
array
No
tag_on_failure
array
No
target
string
No
timezone
string
No
전체 옵션이 필수가 아니긴 합니다.
그래도 꼭 아셔야 하는 설정은 match, target 입니다.
- match 의 첫 번째 값은 field 명이고, 그 이후는 format 들이 되겠습니다.
(공식 문서에 잘 나와 있습니다.)
An array with field name first, and format patterns following, [ field, formats... ]
If your time field has multiple possible formats, you can do this:
match => [ "logdate",
"MMM dd yyyy HH:mm:ss",
"MMM d yyyy HH:mm:ss",
"ISO8601" ]
- target 은 지정을 하지 않게 되면 기본 @timestamp 필드로 설정이 됩니다. 변경 하고자 하면 target 에 원하시는 field name 을 넣으시면 됩니다.
예제)
date {
match => ["time" , "yyyy-MM-dd'T'HH:mm:ssZ", "yyyy-MM-dd'T'HH:mm:ss.SSSZ"]
target => "@timestamp"
}
date {
match => ["localtime" , "yyyy-MM-dd HH:mm:ssZ"]
target => "time"
}DateFilter.java)
더보기
/*
* Licensed to Elasticsearch under one or more contributor
* license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright
* ownership. Elasticsearch licenses this file to you under
* the Apache License, Version 2.0 (the "License"); you may
* not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing,
* software distributed under the License is distributed on an
* "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
* KIND, either express or implied. See the License for the
* specific language governing permissions and limitations
* under the License.
*/
package org.logstash.filters;
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
import org.joda.time.Instant;
import org.logstash.Event;
import org.logstash.ext.JrubyEventExtLibrary.RubyEvent;
import org.logstash.filters.parser.CasualISO8601Parser;
import org.logstash.filters.parser.JodaParser;
import org.logstash.filters.parser.TimestampParser;
import org.logstash.filters.parser.TimestampParserFactory;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class DateFilter {
private static Logger logger = LogManager.getLogger();
private final String sourceField;
private final String[] tagOnFailure;
private RubyResultHandler successHandler;
private RubyResultHandler failureHandler;
private final List<ParserExecutor> executors = new ArrayList<>();
private final ResultSetter setter;
public interface RubyResultHandler {
void handle(RubyEvent event);
}
public DateFilter(String sourceField, String targetField, List<String> tagOnFailure, RubyResultHandler successHandler, RubyResultHandler failureHandler) {
this(sourceField, targetField, tagOnFailure);
this.successHandler = successHandler;
this.failureHandler = failureHandler;
}
public DateFilter(String sourceField, String targetField, List<String> tagOnFailure) {
this.sourceField = sourceField;
this.tagOnFailure = tagOnFailure.toArray(new String[0]);
if (targetField.equals("@timestamp")) {
this.setter = new TimestampSetter();
} else {
this.setter = new FieldSetter(targetField);
}
}
public void acceptFilterConfig(String format, String locale, String timezone) {
TimestampParser parser = TimestampParserFactory.makeParser(format, locale, timezone);
logger.debug("Date filter with format={}, locale={}, timezone={} built as {}", format, locale, timezone, parser.getClass().getName());
if (parser instanceof JodaParser || parser instanceof CasualISO8601Parser) {
executors.add(new TextParserExecutor(parser, timezone));
} else {
executors.add(new NumericParserExecutor(parser));
}
}
public List<RubyEvent> receive(List<RubyEvent> rubyEvents) {
for (RubyEvent rubyEvent : rubyEvents) {
Event event = rubyEvent.getEvent();
switch (executeParsers(event)) {
case FIELD_VALUE_IS_NULL_OR_FIELD_NOT_PRESENT:
case IGNORED:
continue;
case SUCCESS:
if (successHandler != null) {
successHandler.handle(rubyEvent);
}
break;
case FAIL: // fall through
default:
for (String t : tagOnFailure) {
event.tag(t);
}
if (failureHandler != null) {
failureHandler.handle(rubyEvent);
}
}
}
return rubyEvents;
}
public ParseExecutionResult executeParsers(Event event) {
Object input = event.getField(sourceField);
if (event.isCancelled()) { return ParseExecutionResult.IGNORED; }
if (input == null) { return ParseExecutionResult.FIELD_VALUE_IS_NULL_OR_FIELD_NOT_PRESENT; }
for (ParserExecutor executor : executors) {
try {
Instant instant = executor.execute(input, event);
setter.set(event, instant);
return ParseExecutionResult.SUCCESS;
} catch (IllegalArgumentException | IOException e) {
// do nothing, try next ParserExecutor
}
}
return ParseExecutionResult.FAIL;
}
}
Elastic 2019. 11. 5. 14:52
Elastic Stack 의 Reference 목차 입니다.
이걸 왜 한 장으로 정리를 했냐면 목차만 잘 찾아 봐도 해결 방법이 어딨는지 어떤 기능을 제공 하고 있는지 쉽게 알수 있습니다.
(In my case!!)
그래서 혼자 보기 아까워서 그냥 올려봤습니다.
Elastic Stack References)
1. Elasticsearch
2. Logstash
3. Kibana
4. Beats Platform
5. Beats Developer Guide
6. Filebeat
더보기
Elasticsearch
Elasticsearch introduction
Data in: documents and indices
Information out: search and analyze
Scalability and resilience
Getting Started with Elasticsearch
Get Elasticsearch up and running
Index some documents
Start searching
Analyze results with aggregations
Where to go from here
Set up Elasticsearch
Installing Elasticsearch
Install Elasticsearch from archive on Linux or MacOS
Install Elasticsearch with .zip on Windows
Install Elasticsearch with Debian Package
Install Elasticsearch with RPM
Install Elasticsearch Windows MSI Installer
Install Elasticsearch with Docker
Install Elasticsearch on macOS with Homebrew
Configuring Elasticsearch
Setting JVM options
Secure settings
Logging configuration
Auditing settings
Cross-cluster replication settings
Transforms settings
Index lifecycle management settings
License settings
Machine learning settings
Security settings
SQL access settings
Watcher settings
Important Elasticsearch configuration
path.data and path.logs
cluster.name
node.name
network.host
Discovery and cluster formation settings
Setting the heap size
JVM heap dump path
GC logging
Temp directory
JVM fatal error logs
Important System Configuration
Configuring system settings
Disable swapping
File Descriptors
Virtual memory
Number of threads
DNS cache settings
JNA temporary directory not mounted with noexec
Bootstrap Checks
Heap size check
File descriptor check
Memory lock check
Maximum number of threads check
Max file size check
Maximum size virtual memory check
Maximum map count check
Client JVM check
Use serial collector check
System call filter check
OnError and OnOutOfMemoryError checks
Early-access check
G1GC check
All permission check
Discovery configuration check
Starting Elasticsearch
Stopping Elasticsearch
Adding nodes to your cluster
Set up X-Pack
Configuring X-Pack Java Clients
Bootstrap Checks for X-Pack
Upgrade Elasticsearch
Rolling upgrades
Full cluster restart upgrade
Reindex before upgrading
Reindex in place
Reindex from a remote cluster
Aggregations
Metrics Aggregations
Avg Aggregation
Weighted Avg Aggregation
Cardinality Aggregation
Extended Stats Aggregation
Geo Bounds Aggregation
Geo Centroid Aggregation
Max Aggregation
Min Aggregation
Percentiles Aggregation
Percentile Ranks Aggregation
Scripted Metric Aggregation
Stats Aggregation
Sum Aggregation
Top Hits Aggregation
Value Count Aggregation
Median Absolute Deviation Aggregation
Bucket Aggregations
Adjacency Matrix Aggregation
Auto-interval Date Histogram Aggregation
Children Aggregation
Composite Aggregation
Date Histogram Aggregation
Date Range Aggregation
Diversified Sampler Aggregation
Filter Aggregation
Filters Aggregation
Geo Distance Aggregation
GeoHash grid Aggregation
GeoTile Grid Aggregation
Global Aggregation
Histogram Aggregation
IP Range Aggregation
Missing Aggregation
Parent Aggregation
Range Aggregation
Rare Terms Aggregation
Reverse nested Aggregation
Sampler Aggregation
Significant Terms Aggregation
Significant Text Aggregation
Terms Aggregation
Subtleties of bucketing range fields
Pipeline Aggregations
Avg Bucket Aggregation
Derivative Aggregation
Max Bucket Aggregation
Min Bucket Aggregation
Sum Bucket Aggregation
Stats Bucket Aggregation
Extended Stats Bucket Aggregation
Percentiles Bucket Aggregation
Moving Average Aggregation
Moving Function Aggregation
Cumulative Sum Aggregation
Cumulative Cardinality Aggregation
Bucket Script Aggregation
Bucket Selector Aggregation
Bucket Sort Aggregation
Serial Differencing Aggregation
Matrix Aggregations
Matrix Stats
Caching heavy aggregations
Returning only aggregations
Aggregation Metadata
Returning the type of the aggregation
Query DSL
Query and filter context
Compound queries
Boolean
Boosting
Constant score
Disjunction score
Function score
Full text queries
Intervals
Match
Match boolean prefix
Match phrase
Match phrase prefix
Multi-match
Common Terms Query
Query String
Simple query string
Geo queries
Geo-bounding box
Geo-distance
Geo-polygon
Geo-shape
Shape queries
Shape
Joining queries
Nested
Has child
Has parent
Parent ID
Match all
Span queries
Span containing
Span field masking
Span first
Span multi-term
Span near
Span not
Span or
Span term
Span within
Specialized queries
Distance feature
More like this
Percolate
Rank feature
Script
Script score
Wrapper
Pinned Query
Term-level queries
Exists
Fuzzy
IDs
Prefix
Range
Regexp
Term
Terms
Terms set
Type Query
Wildcard
minimum_should_match parameter
rewrite parameter
Regular expression syntax
Search across clusters
Scripting
How to use scripts
Accessing document fields and special variables
Scripting and security
Painless scripting language
Lucene expressions language
Advanced scripts using script engines
Mapping
Removal of mapping types
Field datatypes
Alias
Arrays
Binary
Boolean
Date
Date nanoseconds
Dense vector
Flattened
Geo-point
Geo-shape
IP
Join
Keyword
Nested
Numeric
Object
Percolator
Range
Rank feature
Rank features
Search-as-you-type
Sparse vector
Text
Token count
Shape
Meta-Fields
_field_names field
_ignored field
_id field
_index field
_meta field
_routing field
_source field
_type field
Mapping parameters
analyzer
normalizer
boost
coerce
copy_to
doc_values
dynamic
enabled
eager_global_ordinals
fielddata
format
ignore_above
ignore_malformed
index
index_options
index_phrases
index_prefixes
fields
norms
null_value
position_increment_gap
properties
search_analyzer
similarity
store
term_vector
Dynamic Mapping
Dynamic field mapping
Dynamic templates
Analysis
Anatomy of an analyzer
Testing analyzers
Analyzers
Configuring built-in analyzers
Fingerprint Analyzer
Keyword Analyzer
Language Analyzers
Pattern Analyzer
Simple Analyzer
Standard Analyzer
Stop Analyzer
Whitespace Analyzer
Custom Analyzer
Normalizers
Tokenizers
Char Group Tokenizer
Classic Tokenizer
Edge NGram Tokenizer
Keyword Tokenizer
Letter Tokenizer
Lowercase Tokenizer
NGram Tokenizer
Path Hierachy Tokenizer
Pattern Tokenizer
Simple Pattern Tokenizer
Simple Pattern Split Tokenizer
Standard Tokenizer
Thai Tokenizer
UAX URL Email Tokenizer
Whitespace Tokenizer
Token Filters
Apostrophe
ASCII Folding Token Filter
CJK bigram
CJK width
Classic Token Filter
Common Grams Token Filter
Compound Word Token Filters
Conditional Token Filter
Decimal Digit Token Filter
Delimited Payload Token Filter
Edge NGram Token Filter
Elision Token Filter
Fingerprint Token Filter
Flatten Graph Token Filter
Hunspell Token Filter
Keep Types Token Filter
Keep Words Token Filter
Keyword Request Token Filter
KStem Token Filter
Length Token Filter
Limit Token Count Token Filter
Lowercase Token Filter
MinHash Token Filter
Multiplexer Token Filter
NGram Token Filter
Normalization Token Filter
Pattern Capture Token Filter
Pattern Replace Token Filter
Phonetic Token Filter
Porter Stem Token Filter
Predicate Token Filter Script
Remove Duplicates Token Filter
Reverse Token Filter
Shingle Token Filter
Snowball Token Filter
Stemmer Token Filter
Stemmer Override Token Filter
Stop Token Filter
Synonym Token Filter
Synonym Graph Token Filter
Trim Token Filter
Truncate Token Filter
Unique Token Filter
Uppercase Token Filter
Word Delimiter Token Filter
Word Delimiter Graph Token Filter
Character Filters
HTML Strip Char Filter
Mapping Char Filter
Pattern Replace Char Filter
Modules
Discovery and cluster formation
Discovery
Quorum-based decision making
Voting configurations
Bootstrapping a cluster
Adding and removing nodes
Publishing the cluster state
Cluster fault detection
Discovery and cluster formation settings
Shard allocation and cluster-level routing
Cluster level shard allocation
Disk-based shard allocation
Shard allocation awareness
Cluster-level shard allocation filtering
Miscellaneous cluster settings
Local Gateway
Dangling indices
HTTP
Indices
Circuit Breaker
Fielddata
Node Query Cache
Indexing Buffer
Shard request cache
Index recovery
Search Settings
Network Settings
Node
Plugins
Snapshot And Restore
Thread Pool
Transport
Remote clusters
Index modules
Analysis
Index Shard Allocation
Index-level shard allocation filtering
Delaying allocation when a node leaves
Index recovery prioritization
Total shards per node
Mapper
Merge
Similarity module
Slow Log
Store
Preloading data into the file system cache
Translog
History retention
Index Sorting
Use index sorting to speed up conjunctions
Ingest node
Pipeline Definition
Accessing Data in Pipelines
Conditional Execution in Pipelines
Handling Nested Fields in Conditionals
Complex Conditionals
Conditionals with the Pipeline Processor
Conditionals with the Regular Expressions
Handling Failures in Pipelines
Processors
Append Processor
Bytes Processor
Circle Processor
Convert Processor
Date Processor
Date Index Name Processor
Dissect Processor
Dot Expander Processor
Drop Processor
Fail Processor
Foreach Processor
GeoIP Processor
Grok Processor
Gsub Processor
HTML Strip Processor
Join Processor
JSON Processor
KV Processor
Lowercase Processor
Pipeline Processor
Remove Processor
Rename Processor
Script Processor
Set Processor
Set Security User Processor
Split Processor
Sort Processor
Trim Processor
Uppercase Processor
URL Decode Processor
User Agent processor
Managing the index lifecycle
Getting started with index lifecycle management
Policy phases and actions
Timing
Phase Execution
Actions
Full Policy
Set up index lifecycle management policy
Applying a policy to an index template
Apply a policy to a create index request
Using policies to manage index rollover
Skipping Rollover
Update policy
Updates to policies not managing indices
Updates to executing policies
Switching policies for an index
Index lifecycle error handling
Restoring snapshots of managed indices
Start and stop index lifecycle management
Using ILM with existing indices
Managing existing periodic indices with ILM
Reindexing via ILM
Getting started with snapshot lifecycle management
SQL access
Overview
Getting Started with SQL
Conventions and Terminology
Mapping concepts across SQL and Elasticsearch
Security
SQL REST API
Overview
Response Data Formats
Paginating through a large response
Filtering using Elasticsearch query DSL
Columnar results
Supported REST parameters
SQL Translate API
SQL CLI
SQL JDBC
API usage
SQL ODBC
Driver installation
Configuration
SQL Client Applications
DBeaver
DbVisualizer
Microsoft Excel
Microsoft Power BI Desktop
Microsoft PowerShell
MicroStrategy Desktop
Qlik Sense Desktop
SQuirreL SQL
SQL Workbench/J
Tableau Desktop
SQL Language
Lexical Structure
SQL Commands
DESCRIBE TABLE
SELECT
SHOW COLUMNS
SHOW FUNCTIONS
SHOW TABLES
Data Types
Index patterns
Frozen Indices
Functions and Operators
Comparison Operators
Logical Operators
Math Operators
Cast Operators
LIKE and RLIKE Operators
Aggregate Functions
Grouping Functions
Date/Time and Interval Functions and Operators
Full-Text Search Functions
Mathematical Functions
String Functions
Type Conversion Functions
Geo Functions
Conditional Functions And Expressions
System Functions
Reserved keywords
SQL Limitations
Monitor a cluster
Overview
How it works
Monitoring in a production environment
Collecting monitoring data
Pausing data collection
Collecting monitoring data with Metricbeat
Collecting log data with Filebeat
Configuring indices for monitoring
Collectors
Exporters
Local exporters
HTTP exporters
Troubleshooting
Frozen indices
Best practices
Searching a frozen index
Monitoring frozen indices
Roll up or transform your data
Rolling up historical data
Overview
API quick reference
Getting started
Understanding groups
Rollup aggregation limitations
Rollup search limitations
Transforming data
Overview
When to use transforms
How checkpoints work
API quick reference
Tutorial: Transforming the eCommerce sample data
Examples
Troubleshooting
Limitations
Set up a cluster for high availability
Back up a cluster
Back up the data
Back up the cluster configuration
Back up the security configuration
Restore the security configuration
Restore the data
Cross-cluster replication
Overview
Requirements for leader indices
Automatically following indices
Getting started with cross-cluster replication
Remote recovery
Upgrading clusters
Secure a cluster
Overview
Configuring security
Encrypting communications in Elasticsearch
Encrypting communications in an Elasticsearch Docker Container
Enabling cipher suites for stronger encryption
Separating node-to-node and client traffic
Configuring an Active Directory realm
Configuring a file realm
Configuring an LDAP realm
Configuring a native realm
Configuring a PKI realm
Configuring a SAML realm
Configuring a Kerberos realm
Security files
FIPS 140-2
How security works
User authentication
Built-in users
Internal users
Realms
Realm chains
Active Directory user authentication
File-based user authentication
LDAP user authentication
Native user authentication
PKI user authentication
SAML authentication
Kerberos authentication
Integrating with other authentication systems
Enabling anonymous access
Controlling the user cache
Configuring SAML single-sign-on on the Elastic Stack
The identity provider
Configure Elasticsearch for SAML authentication
Generating SP metadata
Configuring role mappings
User metadata
Configuring Kibana
Troubleshooting SAML Realm Configuration
Configuring single sign-on to the Elastic Stack using OpenID Connect
The OpenID Connect Provider
Configure Elasticsearch for OpenID Connect authentication
Configuring role mappings
User metadata
Configuring Kibana
OpenID Connect without Kibana
User authorization
Built-in roles
Defining roles
Security privileges
Document level security
Field level security
Granting privileges for indices and aliases
Mapping users and groups to roles
Setting up field and document level security
Submitting requests on behalf of other users
Configuring authorization delegation
Customizing roles and authorization
Auditing security events
Audit event types
Logfile audit output
Auditing search queries
Encrypting communications
Setting up TLS on a cluster
Restricting connections with IP filtering
Cross cluster search, clients, and integrations
Cross cluster search and security
Java Client and security
HTTP/REST clients and security
ES-Hadoop and Security
Beats and Security
Monitoring and security
Tutorial: Getting started with security
Enable Elasticsearch security features
Create passwords for built-in users
Add the built-in user to Kibana
Configure authentication
Create users
Assign roles
Add user information in Logstash
View system metrics in Kibana
Tutorial: Encrypting communications
Generate certificates
Encrypt internode communications
Add nodes to your cluster
Troubleshooting
Some settings are not returned via the nodes settings API
Authorization exceptions
Users command fails due to extra arguments
Users are frequently locked out of Active Directory
Certificate verification fails for curl on Mac
SSLHandshakeException causes connections to fail
Common SSL/TLS exceptions
Common Kerberos exceptions
Common SAML issues
Internal Server Error in Kibana
Setup-passwords command fails due to connection failure
Failures due to relocation of the configuration files
Limitations
Alerting on cluster and index events
Getting started with Watcher
How Watcher works
Encrypting sensitive data in Watcher
Inputs
Simple input
Search input
HTTP input
Chain input
Triggers
Schedule trigger
Conditions
Always condition
Never condition
Compare condition
Array compare condition
Script condition
Actions
Running an action for each element in an array
Adding conditions to actions
Email action
Webhook action
Index action
Logging Action
Slack Action
PagerDuty action
Jira action
Transforms
Search transform
Script transform
Chain transform
Java API
Managing watches
Example watches
Watching the status of an Elasticsearch cluster
Watching event data
Troubleshooting
Limitations
Command line tools
elasticsearch-certgen
elasticsearch-certutil
elasticsearch-croneval
elasticsearch-migrate
elasticsearch-node
elasticsearch-saml-metadata
elasticsearch-setup-passwords
elasticsearch-shard
elasticsearch-syskeygen
elasticsearch-users
How To
General recommendations
Recipes
Mixing exact search with stemming
Getting consistent scoring
Incorporating static relevance signals into the score
Tune for indexing speed
Tune for search speed
Tune your queries with the Profile API
Faster phrase queries with index_phrases
Faster prefix queries with index_prefixes
Tune for disk usage
Testing
Java Testing Framework
Why randomized testing?
Using the Elasticsearch test classes
Unit tests
Integration tests
Randomized testing
Assertions
Glossary of terms
REST APIs
API conventions
Multiple Indices
Date math support in index names
Common options
URL-based access control
cat APIs
cat aliases
cat allocation
cat count
cat fielddata
cat health
cat indices
cat master
cat nodeattrs
cat nodes
cat pending tasks
cat plugins
cat recovery
cat repositories
cat task management
cat thread pool
cat shards
cat segments
cat snapshots
cat templates
Cluster APIs
Cluster Health
Cluster State
Cluster Stats
Pending cluster tasks
Cluster Reroute
Cluster Update Settings
Cluster Get Settings
Nodes Stats
Nodes Info
Nodes Feature Usage
Remote Cluster Info
Task management
Nodes hot_threads
Cluster Allocation Explain API
Voting Configuration Exclusions
Cross-cluster replication APIs
Get CCR stats
Create follower
Pause follower
Resume follower
Unfollow
Forget follower
Get follower stats
Get follower info
Create auto-follow pattern
Delete auto-follow pattern
Get auto-follow pattern
Document APIs
Reading and Writing documents
Index
Get
Delete
Delete by query
Update
Update By Query API
Multi get
Bulk
Reindex
Term vectors
Multi term vectors
?refresh
Optimistic concurrency control
Explore API
Index APIs
Add index alias
Analyze
Clear cache
Clone index
Close index
Create index
Delete index
Delete index alias
Delete index template
Flush
Force merge
Freeze index
Get field mapping
Get index
Get index alias
Get index settings
Get index template
Get mapping
Index alias exists
Index exists
Index recovery
Index segments
Index shard stores
Index stats
Index template exists
Open index
Put index template
Put mapping
Refresh
Rollover index
Shrink index
Split index
Synced flush
Type exists
Unfreeze index
Update index alias
Update index settings
Index lifecycle management API
Create policy
Get policy
Delete policy
Move to step
Remove policy
Retry policy
Get index lifecycle management status
Explain lifecycle
Start index lifecycle management
Stop index lifecycle management
Ingest APIs
Put pipeline
Get pipeline
Delete pipeline
Simulate pipeline
Info API
Licensing APIs
Delete license
Get license
Get trial status
Start trial
Get basic status
Start basic
Update license
Machine learning anomaly detection APIs
Add events to calendar
Add jobs to calendar
Close jobs
Create jobs
Create calendar
Create datafeeds
Create filter
Delete calendar
Delete datafeeds
Delete events from calendar
Delete filter
Delete forecast
Delete jobs
Delete jobs from calendar
Delete model snapshots
Delete expired data
Find file structure
Flush jobs
Forecast jobs
Get buckets
Get calendars
Get categories
Get datafeeds
Get datafeed statistics
Get influencers
Get jobs
Get job statistics
Get machine learning info
Get model snapshots
Get overall buckets
Get scheduled events
Get filters
Get records
Open jobs
Post data to jobs
Preview datafeeds
Revert model snapshots
Set upgrade mode
Start datafeeds
Stop datafeeds
Update datafeeds
Update filter
Update jobs
Update model snapshots
Machine learning data frame analytics APIs
Create data frame analytics jobs
Delete data frame analytics jobs
Evaluate data frame analytics
Estimate memory usage for data frame analytics jobs
Get data frame analytics jobs
Get data frame analytics jobs stats
Start data frame analytics jobs
Stop data frame analytics jobs
Migration APIs
Deprecation info
Reload search analyzers
Rollup APIs
Create rollup jobs
Delete rollup jobs
Get job
Get rollup caps
Get rollup index caps
Rollup search
Rollup job configuration
Start rollup jobs
Stop rollup jobs
Search APIs
Search
URI Search
Request Body Search
Search Template
Multi Search Template
Search Shards API
Suggesters
Multi Search API
Count API
Validate API
Explain API
Profile API
Field Capabilities API
Ranking Evaluation API
Security APIs
Authenticate
Change passwords
Clear cache
Clear roles cache
Create API keys
Create or update application privileges
Create or update role mappings
Create or update roles
Create or update users
Delegate PKI authentication
Delete application privileges
Delete role mappings
Delete roles
Delete users
Disable users
Enable users
Get API key information
Get application privileges
Get builtin privileges
Get role mappings
Get roles
Get token
Get users
Has privileges
Invalidate API key
Invalidate token
OpenID Connect Prepare Authentication API
OpenID Connect authenticate API
OpenID Connect logout API
SSL certificate
Snapshot lifecycle management API
Put snapshot lifecycle policy
Get snapshot lifecycle policy
Execute snapshot lifecycle policy
Delete snapshot lifecycle policy
Transform APIs
Create transforms
Update transforms
Delete transforms
Get transforms
Get transform statistics
Preview transforms
Start transforms
Stop transforms
Watcher APIs
Ack watch
Activate watch
Deactivate watch
Delete watch
Execute watch
Get watch
Get Watcher stats
Put watch
Start watch service
Stop watch service
Definitions
Datafeed resources
Data frame analytics job resources
Data frame analytics evaluation resources
Job resources
Job statistics
Model snapshot resources
Role mapping resources
Results resources
Transform resources
Logstash
Logstash Introduction
Getting Started with Logstash
Installing Logstash
Stashing Your First Event
Parsing Logs with Logstash
Stitching Together Multiple Input and Output Plugins
How Logstash Works
Execution Model
Setting Up and Running Logstash
Logstash Directory Layout
Logstash Configuration Files
logstash.yml
Secrets keystore for secure settings
Running Logstash from the Command Line
Running Logstash as a Service on Debian or RPM
Running Logstash on Docker
Configuring Logstash for Docker
Running Logstash on Windows
Logging
Shutting Down Logstash
Setting Up X-Pack
Upgrading Logstash
Upgrading Using Package Managers
Upgrading Using a Direct Download
Upgrading between minor versions
Upgrading Logstash to 7.0
Upgrading with the Persistent Queue Enabled
Configuring Logstash
Structure of a Config File
Accessing Event Data and Fields in the Configuration
Using Environment Variables in the Configuration
Logstash Configuration Examples
Multiple Pipelines
Pipeline-to-Pipeline Communication
Reloading the Config File
Managing Multiline Events
Glob Pattern Support
Converting Ingest Node Pipelines
Logstash-to-Logstash Communication
Centralized Pipeline Management
X-Pack security
X-Pack Settings
Managing Logstash
Centralized Pipeline Management
Working with Logstash Modules
Using Elastic Cloud
ArcSight Module
Netflow Module (deprecated)
Azure Module
Working with Filebeat Modules
Use ingest pipelines for parsing
Use Logstash pipelines for parsing
Example: Set up Filebeat modules to work with Kafka and Logstash
Data Resiliency
Persistent Queues
Dead Letter Queues
Transforming Data
Performing Core Operations
Deserializing Data
Extracting Fields and Wrangling Data
Enriching Data with Lookups
Deploying and Scaling Logstash
Performance Tuning
Performance Troubleshooting Guide
Tuning and Profiling Logstash Performance
Monitoring Logstash with APIs
Node Info API
Plugins Info API
Node Stats API
Hot Threads API
Monitoring Logstash with X-Pack
Metricbeat collection
Internal collection
Monitoring UI
Pipeline Viewer UI
Troubleshooting
Working with plugins
Generating Plugins
Offline Plugin Management
Private Gem Repositories
Event API
Input plugins
azure_event_hubs
beats
cloudwatch
couchdb_changes
dead_letter_queue
elasticsearch
exec
file
ganglia
gelf
generator
github
google_cloud_storage
google_pubsub
graphite
heartbeat
http
http_poller
imap
irc
java_generator
java_stdin
jdbc
jms
jmx
kafka
kinesis
log4j
lumberjack
meetup
pipe
puppet_facter
rabbitmq
redis
relp
rss
s3
salesforce
snmp
snmptrap
sqlite
sqs
stdin
stomp
syslog
tcp
twitter
udp
unix
varnishlog
websocket
wmi
xmpp
Output plugins
boundary
circonus
cloudwatch
csv
datadog
datadog_metrics
elastic_app_search
elasticsearch
email
exec
file
ganglia
gelf
google_bigquery
google_cloud_storage
google_pubsub
graphite
graphtastic
http
influxdb
irc
java_sink
java_stdout
juggernaut
kafka
librato
loggly
lumberjack
metriccatcher
mongodb
nagios
nagios_nsca
opentsdb
pagerduty
pipe
rabbitmq
redis
redmine
riak
riemann
s3
sns
solr_http
sqs
statsd
stdout
stomp
syslog
tcp
timber
udp
webhdfs
websocket
xmpp
zabbix
Filter plugins
aggregate
alter
bytes
cidr
cipher
clone
csv
date
de_dot
dissect
dns
drop
elapsed
elasticsearch
environment
extractnumbers
fingerprint
geoip
grok
http
i18n
java_uuid
jdbc_static
jdbc_streaming
json
json_encode
kv
memcached
metricize
metrics
mutate
prune
range
ruby
sleep
split
syslog_pri
threats_classifier
throttle
tld
translate
truncate
urldecode
useragent
uuid
xml
Codec plugins
avro
cef
cloudfront
cloudtrail
collectd
dots
edn
edn_lines
es_bulk
fluent
graphite
gzip_lines
jdots
java_line
java_plain
json
json_lines
line
msgpack
multiline
netflow
nmap
plain
protobuf
rubydebug
Tips and Best Practices
Troubleshooting Common Problems
Contributing to Logstash
How to write a Logstash input plugin
How to write a Logstash codec plugin
How to write a Logstash filter plugin
How to write a Logstash output plugin
Documenting your plugin
Contributing a Patch to a Logstash Plugin
Logstash Plugins Community Maintainer Guide
Submitting your plugin to RubyGems.org and the logstash-plugins repository
Contributing a Java Plugin
How to write a Java input plugin
How to write a Java codec plugin
How to write a Java filter plugin
How to write a Java output plugin
Glossary of Terms
Kibana
Introduction
Set Up Kibana
Installing Kibana
Install Kibana with .tar.gz
Install Kibana with Debian Package
Install Kibana with RPM
Install Kibana on Windows
Install Kibana on macOS with Homebrew
Starting and stopping Kibana
Configuring Kibana
APM settings
Code settings
Development tools settings
Graph settings
Infrastructure UI settings
i18n settings in Kibana
Logs UI settings
Machine learning settings
Monitoring settings
Reporting settings
Secure settings
Security settings
Spaces settings
Running Kibana on Docker
Accessing Kibana
Connect Kibana with Elasticsearch
Using Kibana in a production environment
Upgrading Kibana
Standard upgrade
Troubleshooting saved object migrations
Configuring monitoring
Collecting monitoring data
Collecting monitoring data with Metricbeat
Viewing monitoring data
Configuring security
Authentication
Encrypting communications
Audit Logging
Getting Started
Add sample data
Explore Kibana using sample data
Build your own dashboard
Define your index patterns
Discover your data
Visualize your data
Add visualizations to a dashboard
Discover
Setting the time filter
Searching your data
Kibana Query Language
Lucene query syntax
Saving searches
Saving queries
Change the indices you’re searching
Refresh the search results
Filtering by Field
Viewing Document Data
Viewing Document Context
Viewing Field Data Statistics
Visualize
Creating a Visualization
Saving Visualizations
Using rolled up data in a visualization
Line, Area, and Bar charts
Controls Visualization
Adding Input Controls
Global Options
Data Table
Markdown Widget
Metric
Goal and Gauge
Pie Charts
Coordinate Maps
Region Maps
Timelion
TSVB
Tag Clouds
Heatmap Chart
Vega Graphs
Getting Started with Vega
Vega vs Vega-Lite
Querying Elasticsearch
Elastic Map Files
Vega with a Map
Debugging
Useful Links
Inspecting Visualizations
Dashboard
Create a dashboard
Dashboard-only mode
Canvas
Canvas tutorial
Create a workpad
Showcase your data with elements
Present your workpad
Share your workpad
Canvas function reference
TinyMath functions
Extend your use case
Graph data connections
Using Graph
Configuring Graph
Troubleshooting
Limitations
Machine learning
Elastic Maps
Getting started with Elastic Maps
Creating a new map
Adding a choropleth layer
Adding layers for Elasticsearch data
Saving the map
Adding the map to a dashboard
Heat map layer
Tile layer
Vector layer
Vector styling
Vector style properties
Vector tooltips
Plot big data without plotting too much data
Grid aggregation
Most recent entities
Point to point
Term join
Searching your data
Creating filters from your map
Filtering a single layer
Searching across multiple indices
Connecting to Elastic Maps Service
Upload GeoJSON data
Indexing GeoJSON data tutorial
Elastic Maps troubleshooting
Code
Import your first repo
Repo management
Install language server
Basic navigation
Semantic code navigation
Search
Config for multiple Kibana instances
Infrastructure
Getting started with infrastructure monitoring
Using the Infrastructure app
Viewing infrastructure metrics
Metrics Explorer
Logs
Getting started with logs monitoring
Using the Logs app
Configuring the Logs data
APM
Getting Started
Visualizing Application Bottlenecks
Using APM
Filters
Services overview
Traces overview
Transaction overview
Span timeline
Errors overview
Metrics overview
Machine Learning integration
APM Agent configuration
Advanced queries
Uptime
Overview
Monitor
SIEM
Using the SIEM UI
Anomaly Detection with Machine Learning
Dev Tools
Console
Profiling queries and aggregations
Getting Started
Profiling a more complicated query
Rendering pre-captured profiler JSON
Debugging grok expressions
Stack Monitoring
Beats Metrics
Cluster Alerts
Elasticsearch Metrics
Kibana Metrics
Logstash Metrics
Troubleshooting
Management
License Management
Index patterns
Cross-cluster search
Rollup jobs
Index lifecycle policies
Creating an index lifecycle policy
Managing index lifecycle policies
Adding a policy to an index
Example of using an index lifecycle policy
Managing Fields
String Field Formatters
Date Field Formatters
Geographic Point Field Formatters
Numeric Field Formatters
Scripted Fields
Index management
Setting advanced options
Saved objects
Managing Beats
Working with remote clusters
Snapshot and Restore
Spaces
Security
Granting access to Kibana
Kibana role management
Kibana privileges
Watcher
Upgrade Assistant
Reporting from Kibana
Automating report generation
PDF layout modes
Reporting configuration
Reporting and security
Secure the reporting endpoints
Chromium sandbox
Troubleshooting
Reporting integration
REST API
Features API
Get features
Kibana Spaces APIs
Create space
Update space
Get space
Get all spaces
Delete space
Copy saved objects to space
Resolve copy to space conflicts
Kibana role management APIs
Create or update role
Get specific role
Get all roles
Delete role
Saved objects APIs
Get object
Bulk get objects
Find objects
Create object
Bulk create objects
Update object
Delete object
Export objects
Import objects
Resolve import errors
Dashboard import and export APIs
Import dashboard
Dashboard export
Logstash configuration management APIs
Create pipeline
Retrieve pipeline
Delete pipeline
List pipeline
URL shortening API
Shorten URL
Upgrade assistant APIs
Upgrade readiness status
Start or resume reindex
Check reindex status
Cancel reindex
Kibana plugins
Install plugins
Update and remove plugins
Disable plugins
Configure the plugin manager
Known Plugins
Limitations
Nested Objects
Exporting data
Developer guide
Core Development
Considerations for basePath
Managing Dependencies
Modules and Autoloading
Communicating with Elasticsearch
Unit Testing
Functional Testing
Plugin Development
Plugin Resources
UI Exports
Plugin feature registration
Functional Tests for Plugins
Localization for plugins
Developing Visualizations
Embedding Visualizations
Developing Visualizations
Visualization Factory
Visualization Editors
Visualization Request Handlers
Visualization Response Handlers
Vis object
AggConfig object
Add Data Guide
Security
Role-based access control
Pull request review guidelines
Interpreting CI Failures
Beats Platform
Community Beats
Getting started with Beats
Config file format
Namespacing
Config file data types
Environment variables
Reference variables
Config file ownership and permissions
Command line arguments
YAML tips and gotchas
Upgrading
Upgrade between minor versions
Upgrade from 6.x to 7.x
Troubleshooting Beats upgrade issues
Beats Developer Guide
Contributing to Beats
Community Beats
Creating a New Beat
Getting Ready
Overview
Generating Your Beat
Fetching Dependencies and Setting up the Beat
Building and Running the Beat
The Beater Interface
Sharing Your Beat with the Community
Naming Conventions
Creating New Kibana Dashboards
Importing Existing Beat Dashboards
Building Your Own Beat Dashboards
Generating the Beat Index Pattern
Exporting New and Modified Beat Dashboards
Archiving Your Beat Dashboards
Sharing Your Beat Dashboards
Adding a New Protocol to Packetbeat
Getting Ready
Protocol Modules
Testing
Extending Metricbeat
Overview
Creating a Metricset
Metricset Details
Creating a Metricbeat Module
Creating a Beat based on Metricbeat
Metricbeat Developer FAQ
Creating a New Filebeat Module
Migrating dashboards from Kibana 5.x to 6.x
Filebeat
Overview
Getting Started With Filebeat
Step 1: Install Filebeat
Step 2: Configure Filebeat
Step 3: Load the index template in Elasticsearch
Step 4: Set up the Kibana dashboards
Step 5: Start Filebeat
Step 6: View the sample Kibana dashboards
Quick start: modules for common log formats
Repositories for APT and YUM
Setting up and running Filebeat
Directory layout
Secrets keystore
Command reference
Running Filebeat on Docker
Running Filebeat on Kubernetes
Filebeat and systemd
Stopping Filebeat
Upgrading Filebeat
How Filebeat works
Configuring Filebeat
Specify which modules to run
Configure inputs
Manage multiline messages
Specify general settings
Load external configuration files
Configure the internal queue
Configure the output
Configure index lifecycle management
Load balance the output hosts
Specify SSL settings
Filter and enhance the exported data
Parse data by using ingest node
Enrich events with geoIP information
Configure project paths
Configure the Kibana endpoint
Load the Kibana dashboards
Load the Elasticsearch index template
Configure logging
Use environment variables in the configuration
Autodiscover
YAML tips and gotchas
Regular expression support
HTTP Endpoint
filebeat.reference.yml
Beats central management
How central management works
Enroll Beats in central management
Modules
Modules overview
Apache module
Auditd module
AWS module
CEF module
Cisco module
Coredns Module
Elasticsearch module
Envoyproxy Module
Google Cloud module
haproxy module
IBM MQ module
Icinga module
IIS module
Iptables module
Kafka module
Kibana module
Logstash module
MongoDB module
MSSQL module
MySQL module
nats module
NetFlow module
Nginx module
Osquery module
Palo Alto Networks module
PostgreSQL module
RabbitMQ module
Redis module
Santa module
Suricata module
System module
Traefik module
Zeek (Bro) Module
Exported fields
Apache fields
Auditd fields
AWS fields
Beat fields
Decode CEF processor fields fields
CEF fields
Cisco fields
Cloud provider metadata fields
Coredns fields
Docker fields
ECS fields
elasticsearch fields
Envoyproxy fields
Google Cloud fields
haproxy fields
Host fields
ibmmq fields
Icinga fields
IIS fields
iptables fields
Jolokia Discovery autodiscover provider fields
Kafka fields
kibana fields
Kubernetes fields
Log file content fields
logstash fields
mongodb fields
mssql fields
MySQL fields
nats fields
NetFlow fields
NetFlow fields
Nginx fields
Osquery fields
panw fields
PostgreSQL fields
Process fields
RabbitMQ fields
Redis fields
s3 fields
Google Santa fields
Suricata fields
System fields
Traefik fields
Zeek fields
Monitoring Filebeat
Internal collection
Settings for internal monitoring collection
Metricbeat collection
Securing Filebeat
Secure communication with Elasticsearch
Secure communication with Logstash
Use X-Pack security
Grant users access to secured resources
Configure authentication credentials
Configure Filebeat to use encrypted connections
Use Linux Secure Computing Mode (seccomp)
Troubleshooting
Get help
Debug
Common problems
Can’t read log files from network volumes
Filebeat isn’t collecting lines from a file
Too many open file handlers
Registry file is too large
Inode reuse causes Filebeat to skip lines
Log rotation results in lost or duplicate events
Open file handlers cause issues with Windows file rotation
Filebeat is using too much CPU
Dashboard in Kibana is breaking up data fields incorrectly
Fields are not indexed or usable in Kibana visualizations
Filebeat isn’t shipping the last line of a file
Filebeat keeps open file handlers of deleted files for a long time
Filebeat uses too much bandwidth
Error loading config file
Found unexpected or unknown characters
Logstash connection doesn’t work
@metadata is missing in Logstash
Not sure whether to use Logstash or Beats
SSL client fails to connect to Logstash
Monitoring UI shows fewer Beats than expected
A. Contributing to Beats
Elastic/Logstash 2019. 11. 4. 14:16
공홈에 올라와 있는 문서의 번역 본 정도로 정리를 해보려고 합니다.
별거 아니지만 JSON filter 를 많이 사용하면서 Validation 에 대한 인식이 부족해서 오류를 발생 시키는 경우가 꽤 많이 있습니다.
기억력을 돕기 위해 작성해 봅니다.
공식문서)
https://www.elastic.co/guide/en/logstash/current/plugins-filters-json.html
이 내용은 logstash reference 문서 내 filter 항목에 해당 합니다.
용도는 말 그대로 입니다. JSON parsing 을 하는 filter 입니다.
여기서 문제가 들어 오는 JSON 데이터가 항상 validate 할 거라고 생각 하고 구현 하시는 분들이 계시는데 이 부분이 문제가 됩니다.
기본 이라고 생각 하지만 validation 에 대한 개발자의 생각과 경험이 요즘은 다른 것 같더라구요.
암튼, 그래서 JSON filter 사용 시 제공하는 Option 에 대해서 숙지 하고 사용하시면 좋겠습니다.
기본적으로는 Common Options 를 먼저 보시는게 좋습니다.
JSON Filter Configuration Options)
Setting Input type Required
skip_on_invalid_json
boolean
No
source
string
Yes
tag_on_failure
array
No
target
string
No
위 설정 중에서 skip_on_invalid_json 과 tag_on_failure 만 잘 설정 하셔도 invalid data 에 대한 오류는 잘 넘길 수 있습니다.
간혹 이 오류로 인해서 logstash 가 먹통이 되는 걸 예방 할 수 있기 때문 입니다.
Elastic/Elasticsearch 2019. 10. 23. 09:58
저는 기본적으로 API 단에서 Elasticsearch 로 질의한 결과를 Cache 하도록 구현해서 사용하고 있습니다.
하지만 Elasticsearch 에서도 기본적으로 두 가지의 Cache 기능을 제공 하고 있으니 잘 활용 하시면 좋을 것 같아 기록해 봅니다.
한 줄로 정리 하면)
검색 결과 리스팅은 Query Cache에, 검색 결과에 대한 집계 는 Request Cache 에 저장 된다고 이해 하시면 됩니다.
1. Node Query Cache
공식문서)
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-cache.html
- 이 기능은 Query 에 따른 결과를 Cache하게 되며, LRU 정책으로 동작 합니다.
- 이 기능은 Node 레벨로 동작 합니다.
- 이 기능은 Filter Context 를 사용 했을 경우에만 동작 합니다.
- 아래 설정은 Cluster 내 모든 Data Node 에 설정을 반드시 해야 합니다.
indices.queries.cache.size
- 아래 설정은 Index 별로 설정을 해야 합니다.
2. Shard Request Cache
공식문서)
https://www.elastic.co/guide/en/elasticsearch/reference/current/shard-request-cache.html
- 이 기능은 개별 Local Shard 의 결과를 Cache 합니다.
- 이 기능은 size=0 인 Request 의 결과만 Cache 합니다.
- 즉, Aggregations 와 Suggestions 결과를 Cache 하게 되며, hits 결과는 Cache 하지 않지만 hits.total 은 Cache 합니다.
- Date Range 또는 Histogram 질의 시 now 를 사용하게 되면 Cache 하지 않습니다.
- 이 기능은 Index 레벨로 설정을 합니다.
PUT /my_index
- 아래 설정은 Node 레벨로 설정을 하는 것입니다.
indices.requests.cache.size
- 아래 설정은 Cache TTL 설정을 하는 것입니다.
indices.requests.cache.expire
Code Sniff)
// IndicesRequestCache.java
/**
* A setting to enable or disable request caching on an index level. Its dynamic by default
* since we are checking on the cluster state IndexMetaData always.
*/
public static final Setting<Boolean> INDEX_CACHE_REQUEST_ENABLED_SETTING =
Setting.boolSetting("index.requests.cache.enable", true, Property.Dynamic, Property.IndexScope);
public static final Setting<ByteSizeValue> INDICES_CACHE_QUERY_SIZE =
Setting.memorySizeSetting("indices.requests.cache.size", "1%", Property.NodeScope);
public static final Setting<TimeValue> INDICES_CACHE_QUERY_EXPIRE =
Setting.positiveTimeSetting("indices.requests.cache.expire", new TimeValue(0), Property.NodeScope);
// TimeValue.java
public static TimeValue parseTimeValue(String sValue, TimeValue defaultValue, String settingName) {
settingName = Objects.requireNonNull(settingName);
if (sValue == null) {
return defaultValue;
}
final String normalized = sValue.toLowerCase(Locale.ROOT).trim();
if (normalized.endsWith("nanos")) {
return new TimeValue(parse(sValue, normalized, "nanos"), TimeUnit.NANOSECONDS);
} else if (normalized.endsWith("micros")) {
return new TimeValue(parse(sValue, normalized, "micros"), TimeUnit.MICROSECONDS);
} else if (normalized.endsWith("ms")) {
return new TimeValue(parse(sValue, normalized, "ms"), TimeUnit.MILLISECONDS);
} else if (normalized.endsWith("s")) {
return new TimeValue(parse(sValue, normalized, "s"), TimeUnit.SECONDS);
} else if (sValue.endsWith("m")) {
// parsing minutes should be case-sensitive as 'M' means "months", not "minutes"; this is the only special case.
return new TimeValue(parse(sValue, normalized, "m"), TimeUnit.MINUTES);
} else if (normalized.endsWith("h")) {
return new TimeValue(parse(sValue, normalized, "h"), TimeUnit.HOURS);
} else if (normalized.endsWith("d")) {
return new TimeValue(parse(sValue, normalized, "d"), TimeUnit.DAYS);
} else if (normalized.matches("-0*1")) {
return TimeValue.MINUS_ONE;
} else if (normalized.matches("0+")) {
return TimeValue.ZERO;
} else {
// Missing units:
throw new IllegalArgumentException("failed to parse setting [" + settingName + "] with value [" + sValue +
"] as a time value: unit is missing or unrecognized");
}
}
각 설정 값들에 대한 최적화는
- 장비 스펙
- 질의 특성
- 문서 크기
등에 맞춰서 구성을 하셔야 합니다.
잘 모를 경우는 그냥 Elasticsearch 의 default 값을 사용하시면서 최적값을 찾으셔야 합니다.
Monitoring Cache Usage)
공식문서)
https://www.elastic.co/guide/en/elasticsearch/reference/current/cluster-stats.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/cluster-nodes-stats.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/indices-stats.html
GET /_stats/request_cache?human
함께 알아 두면 좋은것)
https://www.elastic.co/guide/en/elasticsearch/reference/current/fielddata.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/doc-values.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-store.html
Elastic/Elasticsearch 2019. 10. 17. 15:13
사용하고자 하는 Software Stack 은 다양하게 많이 있습니다.
일반적으로 아래 파이프라인으로 많이들 구성 합니다.
1. App -> Stream service -> Consumer -> Elasticsearch
이걸 다시 Elastic Stack 으로 변환 하면
Producer 는)
- Filebeat
- Logstash
Queue 는)
- Logstash persistent queue
Consumer 는)
- Logstash
이 외에도 sqs, dynamodb, redis, kafka, fluentd, storm 등 활용 가능한 오픈소스들이 많이 준비되어 있습니다.
가장 쉽고 일반적인 구성이라고 보시면 될 것 같습니다.
Elastic/Elasticsearch 2019. 10. 2. 16:04
기억하기 위해 작성해 봅니다.
ES Cluster 를 아래와 같이 구성 한다고 가정 하고 들어 가겠습니다.
1. Master Node 2개
2. Coordinating Node 2개
3. Data Node 2개
ES Cluster 를 구성 하다 보면 CPU, MEM, DISK, NETWORK 등 모든 자원을 다 효율적으로 사용하도록 구성 하기는 매우 어렵습니다.
그렇다 보니 CPU 는 부족한데 MEM 은 남는 다던가 MEM 은 부족한데 CPU 는 남는 다던가 또는 가끔 말도 안되게 NETWORK Bandwidth 가 부족 할 때도 나오더군요.
암튼 그래서 모든 자원을 다 쥐어 짜듯이 구성 할 수 없으니 적당히 포기 하시길 권장 드립니다.
여기서 Auto Scaling 하는 구성은 Coordinating Node 와 Data node 이 두 가지 입니다.
우선 ES 는 너무 쉽게 Node 를 추가 하고 삭제 할 수 있습니다.
elasticsearch.yml 파일 내 Master Node 정보만 등록 해 두시면 됩니다.
- discovery.zen.ping.unicast.hosts: MASTER_NODE_LIST
설정 공식 문서는 아래 링크 참고 하세요.
https://www.elastic.co/guide/en/elasticsearch/reference/6.2/modules-discovery-zen.html
Zen Discovery | Elasticsearch Reference [6.2] | Elastic
The zen discovery is the built in discovery module for Elasticsearch and the default. It provides unicast discovery, but can be extended to support cloud environments and other forms of discovery. The zen discovery is integrated with other modules, for exa
www.elastic.co
Coordinating Node Auto Scaling 구성 하기)
0. 가장 먼저 하셔야 하는 작업은 elasticsearch.yml 파일 내 Master Node 정보 등록 입니다.
1. 우선 Coordinating Node 들을 LoadBalancer 로 묶습니다. (AWS 를 사용 하시면 ALB/ELB 로 구성 하시면 됩니다.)
- Coordinating Node 의 경우 "Too many requests" 오류가 발생 할 경우 이를 예방 하기 위해 Auto Scaling 구성을 하면 좋습니다.
- 보통 트래픽이 몰릴 경우 search thread 가 부족 할 수 있기 때문 입니다.
- LB 로 묶는 또 다른 이유는 API 단에서 단일 Endpoint 를 바라 보게 해서 운영을 편하게 하기 위함 입니다.
2. Auto Scaling 설정 구성을 합니다.
- 이 부분은 사용하시는 환경에 맞춰서 구성 하시면 됩니다.
- 공식 문서를 참고 하시면 됩니다.
- https://docs.aws.amazon.com/ko_kr/autoscaling/ec2/userguide/scaling_plan.html#scaling_typesof
Auto Scaling 그룹의 크기 조정 - Amazon EC2 Auto Scaling
Auto Scaling 그룹의 크기 조정 조정은 애플리케이션의 컴퓨팅 용량을 늘리거나 줄이는 기능입니다. 조정은 이벤트와 함께 시작되거나 Auto Scaling 그룹에 Amazon EC2 인스턴스를 시작 또는 종료하도록 지시하는 조정 작업과 함께 시작됩니다. Amazon EC2 Auto Scaling에서는 여러 가지 방법으로 애플리케이션의 요구 사항에 가장 적합하게 조정 기능을 조절할 수 있습니다. 그러므로 애플리케이션을 충분히 이해하는 것이 중요합니다.
docs.aws.amazon.com
3. 테스트 해보시고 서비스에 적용 하시면 됩니다.
Data Node Auto Scaling 구성 하기)
0. 가장 먼저 하셔야 하는 작업은 elasticsearch.yml 파일 내 Master Node 정보 등록 입니다.
0. 더불어 Replica Shard 설정은 (Data Node - 1) 만큼 구성이 되어야 합니다.
0. 더불어 초기 Data Node 수와 Primary Shard 크기를 잘 정의 하셔야 합니다.
0. 이유는 Primary Shard 는 한번 생성 하게 되면 ReIndexing 을 하지 않고서는 변경이 불가능 합니다.
1. Auto Scaling 설정 구성을 합니다.
- 이 설정 시 Shard reallocation 에 대한 이슈는 없는지 꼭 확인을 하셔야 합니다.
- CPU, DISk I/O, NETWORK 등에 대한 성능 저하가 발생 할 수 있습니다.
1. Auto Scaling 설정 후 수동으로 Shard Allocation 이 가능 합니다.
- 보통 이런 문제는 트래픽이 몰리거나 운영 시점에 발생을 하기 때문에 미리 스크립트 구성해 놓으시고 re-location 진행 하시면 됩니다.
- 그래서 Shard Allocation 설정을 꺼 두셔야 합니다.
- 공식 문서를 참고 하시면 됩니다.
- https://www.elastic.co/guide/en/elasticsearch/reference/current/shards-allocation.html
Cluster level shard allocation | Elasticsearch Reference [7.4] | Elastic
Regardless of the result of the balancing algorithm, rebalancing might not be allowed due to forced awareness or allocation filtering.
www.elastic.co
2. Data Node 의 경우 Auto Scaling 종료 정책에 따라 Primary Shard 가 유실 되지 않도록 구성 하는 것이 좋습니다.
- 물론 Full Replicaiton 구성이라 다른 Replica 가 Primary Shard 로 선출 되겠지만 그래도 주의 하는게 좋겠죠.
마무리를 하면)
Coordinating Node 까지는 쉽게 적용이 가능 합니다.
하지만, Data Node 적용은 실제 운영 경험이 있고 문제 발생 시 신속하게 대응이 가능 하지 않다면 시도 하지 마시라고 말씀 드리고 싶습니다.